
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- update
- Statistics
- 자연어 논문
- inner join
- leetcode
- nlp논문
- airflow
- sql
- 표준편차
- SQL코테
- CASE
- NLP
- 설명의무
- torch
- 코딩테스트
- t분포
- 카이제곱분포
- 서브쿼리
- 자연어처리
- sigmoid
- 짝수
- Window Function
- LSTM
- 그룹바이
- SQL 날짜 데이터
- 자연어 논문 리뷰
- 논문리뷰
- GRU
- MySQL
- HackerRank
- Today
- Total
HAZEL
[Basic Statistics : CH 1. 모집단과 표본] 모집단과 표본 추출 , 표본의 분포 본문
[Basic Statistics : CH 1. 모집단과 표본] 모집단과 표본 추출 , 표본의 분포
Rmsid01 2020. 6. 21. 00:19CH1. 모집단과 표본
01 . 모집단과 표본 추출
001. 모집단과 표본
- 모집단 : 통계분석 방법을 적용할 관심 대상의 전체 집합
- 표본 : 과학적인 절차를 적용하여 모집단을 대표할 수 있는 일부를 추출하여 직접적인 조사 대상이 된 모집단의 일부

출처: 통계청
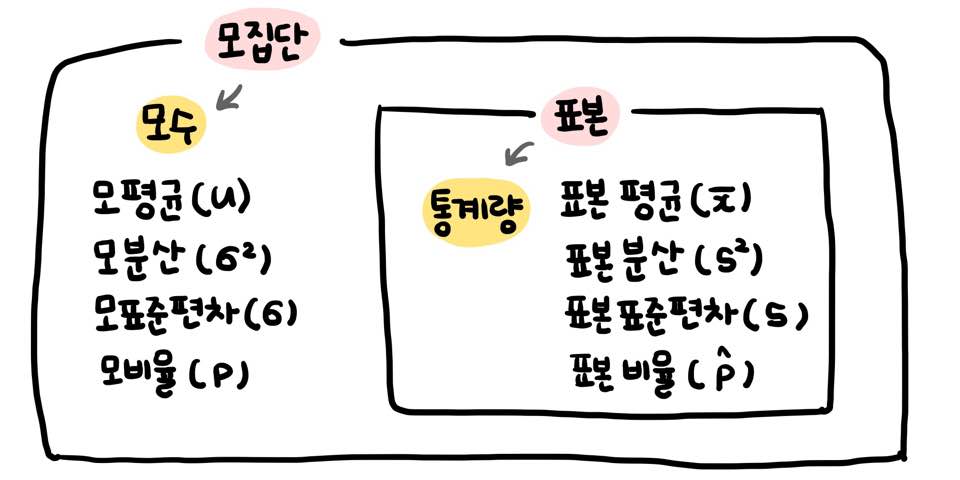
002. 모수와 통계량
- 모수 : 모집단을 분석하여 얻어지는 결과 수치 ( 통계적 수치 ) ex, 모평균 , 모분산 , 모표준편차, 모비율
- 통계량 : 표본을 분석하여 얻어지는 결과 수치 ex, 표본평균, 표본분산, 표본표준편차, 표본비율
003. 표본추출의 방법
1. 확률적 표본추출 방법
: 모집단에서 표본이 될 확률이 모두 동일한것. 표본추출의 방법은 동일한 확률 하에서 표본을 구성
2. 비확률적 표본추출 방법
: 확률과는 상관없이 조사자가 자신의 의지로 표본을 뽑거나 조사 대상이 자발적으로 표본을 구성
표본이 되는 확율이 일정하지 않음
004. 확률적 표본 추출의 종류
1. 단순 무작위 표본 추출
: 모집단에서 일정한 규칙에 따라서 일정하고 추출하는 것
ex, 컴퓨터로 추출하는 것. 난수표 이용
2. 체계적 표본추출
: 전체적인 모집단을 전부다 번호를 붙인 후 일정하고 뽑음
ex, 1,2,3,4...100 의 번호를 붙이고 1, 11, 21, 31, ,,,, 91 을 뽑음
3. 비례 층화 표본 추출
: 모집단을 규칙에 의해 여러개의 집단으로 나눔
ex. 학교에서 1,2,3,4 학년으로 나누고 거기에 따른 비율을 적용해서 뽑음
4. 다단계 층화 표본 추출
ex, 학교에서 단과대로 나누고, 거기에 1,2,3,4 학년으로 나누고 거기에 따른 비율을 적용해서 뽑음
5. 군집 표본 추출
: 모집단의 구성이 내부는 이질적이고 외부는 동질적으로 구성이 되어있을때, 일부분의 군집만 뽑기.
ex, 서울시를 조사할 때, ~~구 로 나뉘어있음. 외부적으로는 동질적이나, 내부는 이질적으로 구성되어있음.
005. 비확률적 표본추출 : 표본이 될 가능성이 다 다름.
1. 편의 표본추출
: 조사자가 마음대로 뽑는것. 조사비용이 절약되나, 실수나 오류가 가장 많이 발생함. 과학적이지 않음.
2. 판단 표본추출
: 편의 표본추출에서 한번더 생각하는 것. 조사자가 한번 생각해서 적합하다고 생각이 드는 것을 추출
3. 할당 표본추출
: 모집단의 학력. 연령, 직업등을 조사한 후, 조사자가 각각을 할당하는 방법
4. 자발적 표본추출
: 표본인들이 스스로 와서 표본이 되기를 원하는 방법, 결과가 왜곡될 가능성이 크다.
02. 표본의 분포
** 여기서는 그냥 '이런종류가 있다.' 정도만 보고 넘어가기 **
001. 정규분포
정규분포 : 표본분포 중에서 가장 단순하면서 많이 나타나는 형태의 분포
-> 어떤 사건이 일어난 빈도를 계산하여 그래프로 나타내면 중심(평균)을 기준으로 좌우가 대칭되는 분포
* 표준화
: 어떤 기준을 만들어 놓고, 기준을 중심으로 새롭게 배치를 하는것. 여기서 기준은 , 평균 =0 분산(표준편차) =1
단순한 현상은 정규분포만을 이용해도 괜찮지만, 복잡한 관계에서 여러 특성에 대한 분석 결과를 비교할 수 있게 하는 과정
002. 표본 정규분포 = Z 분포
x : 측정치 u : 평균
표본의 갯수가 충분할 때 사용함. 30개 이상이면 충분하다고 봄.
30 개의 분포를 추정한것을 z 분포를 이용함.
003. t분포
위의 공식의 차이는 s 이다.
모표준편차가 아닌 표본표준편차를 이용.
표본의 갯수가 충분하지 않을 때 사용함. ( 이유는 중심극한정리 )
t분포는 평균이 0 이고 표준분포가 1보다 큰 것을 다르게 됨.
자유도 : n -1 > 해당하는 측정치에서 1을 뺌
004. 카이제곱 분포 x**2
표준정규분포로 도출이 됨.
기본적으로 z분포에 대한 제곱의 값을 가지고 분포를 나타냄
제곱을 하면 , 0보다 큰 값이 나옴.
자유도가 n 임
확률변수 x 를 제곱한 것. 확률변수 한개에 대한 추론
005. f분포
확률변수 두개 에 해당하는 분산에 대한 추론
f = 분산에 대한 비율이 나옴.
006. p - hat 분포
:표본 비율 p hat 은 모집단의 특성 중 모비율을 추정하기 위해 사용됨
주로 성공 vs 실패, 남 vs 여 구매vs비구매 등과 같이 어느 한 사건이 발생하는 베르누이 시행의 이항분포를 활용하여 표본비율의 분포를 구함
03. 표본분포와 중심극한정리
001. 표본분포
- 표본에서 도출되는 **통계량에 대한 확률 분포,
- 표본분포는 모수를 추정하기 위한 표본 통계량의 확률 분표 (여러 번 측정)
** 통계량 : 표본을 분석하여 얻어지는 결과 수치 ex, 표본평균, 표본분산, 표본표준편차, 표본비율
002. 중심극한정리(Centeral Limit Theorem : CLT)
- 표본평균의 분포는 정규분포에 근사하게 된다.
- 표본의개수(n)가 충분하다면 모수를 모르는 상황에서도 표본 통계량으로 정규분포를 구성하여(정규분포에 가까워져서) 모수를 추정할 수 있다는 것이다.
- 표본의 개수(n)이 충분하다면, 모수와의 오차가 줄어든다.
- 이론적으로는 30개가 표본이 충분하다고는 하지만, 많으면 많을 수록 좋다.
- 모집단의 모양이 어떤것이냐에 상관없이 표본평균의 분포는 정규 분포에 근사하게 됨.
참고 자료 : https://www.youtube.com/watch?v=iTNHQXGIEuU
공부 교재 : 제대로 시작하는 기초통계학
사회조사분석사
https://www.youtube.com/watch?v=jGOqkljySu8&list=PLsri7w6p16vuDN55ZGHVYnitXs2R1Wz6q
'DATA ANALYSIS > Math' 카테고리의 다른 글
| [Basic Statistics : CH 5. 추정] 점추정과 구간추정 , 모평균의 구간 추정, 모집단 비율 및 분산의 구간추정 (0) | 2020.12.01 |
|---|---|
| [Basic Statistics : CH 4. 확률분포] 확률분포, 이항분포, 포아송분포 (0) | 2020.11.10 |
| [Basic Statistics : CH 3. 확률과 통계] 확률과 의사결정, 확률변수의 기대값과 분산 (0) | 2020.11.08 |
| [Basic Statistics : CH 2. 데이터와 통계량] 데이터의 수집(척도), 데이터의 표현방법, 기초 통계량 (0) | 2020.11.06 |
| [Python_Statistics : 1절 기초통계] 용어정리, 실험, 확률 변수와 확률 분포(이산형 확률변수) (0) | 2020.05.28 |



