
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- torch
- t분포
- Statistics
- 자연어 논문 리뷰
- 코딩테스트
- 그룹바이
- 카이제곱분포
- 설명의무
- 짝수
- SQL 날짜 데이터
- sigmoid
- GRU
- 서브쿼리
- 자연어 논문
- 표준편차
- 논문리뷰
- 자연어처리
- inner join
- LSTM
- nlp논문
- HackerRank
- NLP
- SQL코테
- airflow
- Window Function
- leetcode
- update
- MySQL
- sql
- CASE
- Today
- Total
HAZEL
[Basic Statistics : CH 8 . 분산 분석] 분산 분석, 일원 분산분석, 이원 분산분석 본문
[Basic Statistics : CH 8 . 분산 분석] 분산 분석, 일원 분산분석, 이원 분산분석
Rmsid01 2020. 12. 7. 14:38그동안, 정리한 [ 기초 통계 ] 내용 보러 가기
2020/06/21 - [DATA/Statistics] - [Basic Statistics : CH 1. 모집단과 표본] 모집단과 표본 추출 , 표본의 분포
2020/11/06 - [DATA/Statistics] - [Basic Statistics : CH 2. 데이터와 통계량] 데이터의 수집(척도), 데이터의 표현방법, 기초 통계량
2020/11/08 - [DATA/Statistics] - [Basic Statistics : CH 3. 확률과 통계] 확률과 의사결정, 확률변수의 기대값과 분산
2020/11/10 - [DATA/Statistics] - [Basic Statistics : CH 4. 확률분포] 확률분포, 이항분포, 포아송분포
CH8. 분산 분석
01 . 분산 분석
001. 분산분석 이란 ? ( ANalysis Of VAriance : ANOVA )
: 3개 이상의 집단에 대한 평균 차이를 검증하는 분석 방법
: 특성에 대한 산포의 제곱합을 요인별로 분해하는 것
: F분포를 이용함
** 2개 이상의 집단일 경우, 7장에서 살펴보았음.
3개 이상이 넘어가면, 7장의 방법은 불편하기 때문에, 분산분석을 이용하면 편함
002. 분산분석에서의 편차
: 분산분석에서는 중요한 개념이 < 편차 > 라는 개념이다.
1. 총 편차
: 전체 집단 간의 평균과 특정한 점의 차이
2. 집단 간 편차
: 해당하는 집단의 평균과 전체에 해당하는 평균의 차이
3. 집단 내 편차
: 해당 집단내의 평균과 특정값에 대한 차이

- 집단 간의 분산이 크다라고 한다면? 집단 간의 평균 차이가 크다는 의미
- 집단 내의 분산이 작으면? 집단 간의 차이가 커짐.
003. F : 편차의 비율을 가지고 확인하는 것 , 분산 비율

004. 분산 분석의 구분
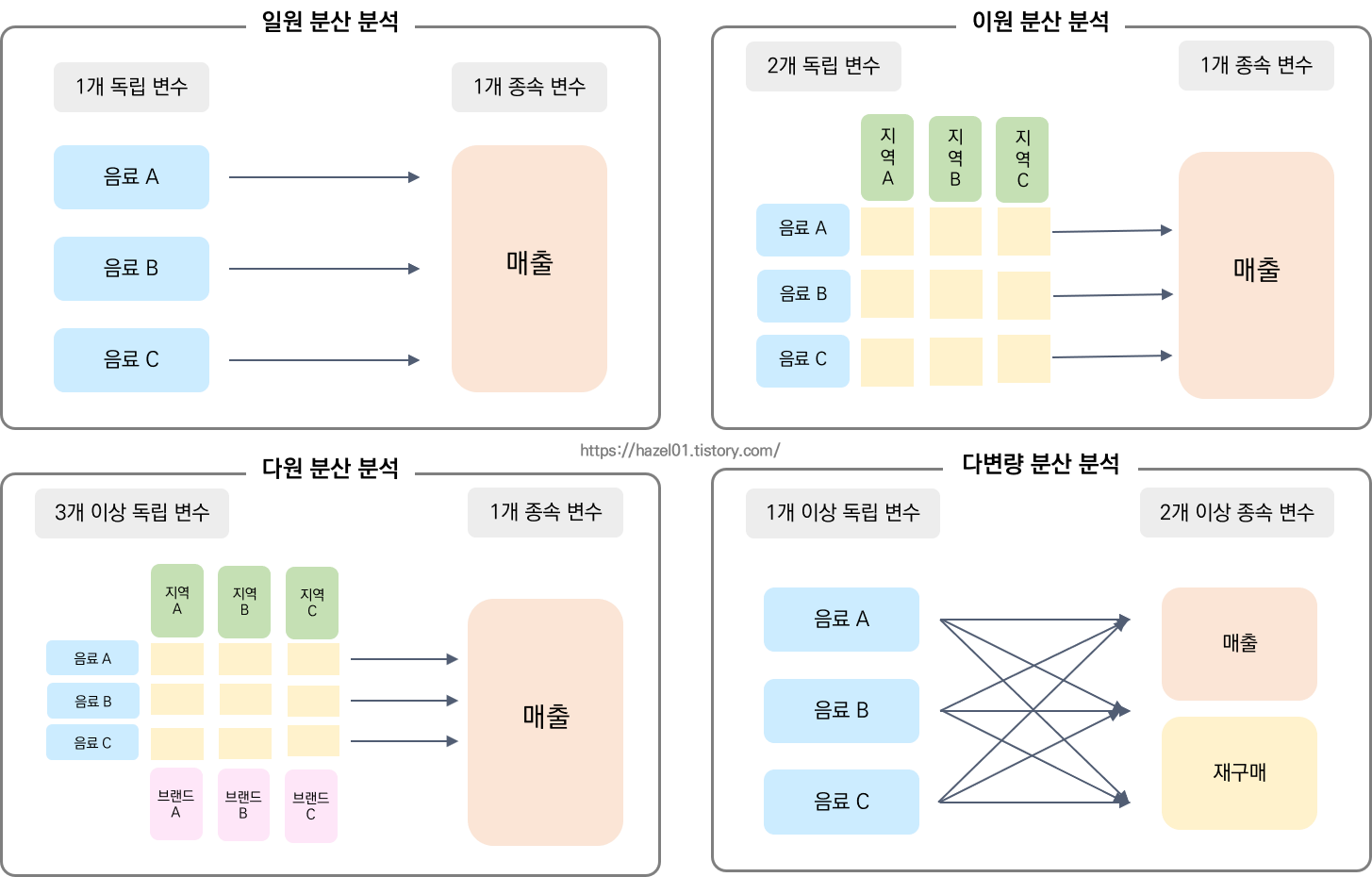
1. 일원 분산분석 ( one - way ANOVA )
: 하나의 다른 척도를 가지고 보는 것을 일원 분산분석이라고 함.
2. 이원 분산분석 ( two -way ANOVA )
: 두 가지 요인을 기준으로 집단 간의 차이를 조사하는 것.
3. 다원 분산 분석 ( multi - way ANOVA )
: 세 가지 이상의 요인을 기준으로 집단 간의 차이를 조사하는 것
4. 다변량 분산분석 ( multi - variate ANOVA )
: 독립변수 1개 이상에 대해 종속변수 2개 이상으로 조사하는 것

004. 분산 분석의 가정
- 각 모집단은 정규 분포여야 하며, 집단 간 분산은 동일해야 한다.
: 평균값이 다르다 하더라도, 겹치는 부분이 다르기 때문에, 분석하기 적합하지 않다.!
- 각 표본들은 독립적으로 추출되어야 한다.
: 각 표본들이 독립적이어야 한다.
: 즉, 각 표본끼리 영향을 주고받으면 안 된다.
- 각 표본의 크기는 적절해야 한다.
: 통계 분석을 진행하기 위해서, 표본의 크기가 충분해야 한다.
02. 일원 분산분석
001. 일원 분산 분석 ( one - way ANOVA )
: 하나의 다른 척도를 가지고 보는 것을 일원 분산분석이라고 함.

002. 가설 수립
: 각 음료에 대한 매출의 차이가 있는지 유의 수준 0.05에서 알아보자!
: 조건 : 음료 A의 평균 : 2.857 , B의 평균 : 4.000, C에 대한 평균 : 3.444, 전체 평균 : 3.434
H0 = 음료에 따른 매출의 차이가 없다.
H1 = 음료에 따른 매출의 차이가 있다.

003. 편차
- 어떤 값을 비교할 때 가장 기본이 되는 값은 평균이다!
: 편차를 자유도로 나누면, 편차의 평균이 된다!
: 여기서! * 주의 * 편차는 각기 다른 자유도를 가진다.
1. SST = n - 1
2. SSB = i - 1
3. SSW = n - i
: 즉, 집단 간 / 내의 편차를 자유도로 나누면 분산이 되게 된다
: 이를 분산 분석이라고 한다.

004. 분산 비율 F

005. 일원 분산 분석표

- 5.664를 어떻게 해석하는가 ?
: 음료 간의 매출이 차이가 있긴 한데,
매출이 가장 높은 것과 작은 것의 차이를 비교했을 때, 5.664배의 매출의 차이가 난다.
006. F 분포도 & 가설 채택

- F분포표를 이용하여, 값 찾기
: 분자(분자(집단 간의 자유도) : 2 / 분모(집단내의 자유도) : 21에 해당하는 F분포표의 수치를 찾기
- 분산비율 F = 5.664 가 나왔으므로, 확률이 0.5 보다 작다는 것을 의미함.
: 즉, 기각역에 해당되고, 귀무가설을 기각하고 대립 가설을 채택함
03. 이원 분산분석
001. 이원 분산분석 ( two -way ANOVA )
: 두 가지 요인을 기준으로 집단 간의 차이를 조사하는 것.

002. 상호작용 효과 ( Interaction effect )
- 사회 과학에서는 독립 변수 끼리 독립적으로 영향을 미치는 것이 아닌, 독립 변수들끼리 복합작용으로 일어나는 효과도 존재
- 실제로는 A에 해당하는 것 B에 해당하는것 뿐만아니라 복합작용(C)도 생각해야 함.

003. 가설 수립
: 각 음료와 각 지역에 대한 ( 두 독립변수에 대한 ) 매출의 차이가 있는지 유의 수준 0.05에서 알아보자! < A 그림 참고 >
: 전체 평균 = 2.926


004. 편차

위의 공식으로 값을 구하면,
SST = 23.852
SSB_i = 7.183 < k_i = 9 >
SSB_j = 0.517 < k_j = 9 >
SSB_ij = 1.481 < k = 3 >
SSW = SST - SSB_i - SSB_j - SSB_ij = 14.671
자유도로 평균제곱을 구하기

MSB_i = 3.592
MSB_j = 0.259
MSB_ij = 0.370
MSW = 0.815
005. 이원 분산 분석표

006. F 분포도 & 가설 채택
- F 분포표에서 F 기각치( F 값 )를 찾으면, 아래의 표와 같은 결과가 나온다.
- F 비가 F 기각치보다 크면 ? P 값이 0.05로 떨어진다. < 독립변수 i >
: 따라서, 귀무가설을 기각하고 대립 가설을 채택한다.
: 즉, 음료에 따라서, 매출의 차이가 있다! 라는 사실을 알 수 있다.
- 교호 작용 ( 상호작용 ) , 지역 ( 독립변수 j ) 는 분산 비율( F 비 ) 가 F 기각치 보다 작다.
: P 값이 0.05 보다 크다
: 귀무가설을 채택한다.
: 즉, 지역에 따라서 , 교호 작용에 따라서 매출의 차이는 없다!

공부 교재 : 제대로 시작하는 기초통계학
사회조사분석사
https://www.youtube.com/watch?v=jGOqkljySu8&list=PLsri7w6p16vuDN55ZGHVYnitXs2R1Wz6q



