
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 카이제곱분포
- 서브쿼리
- 표준편차
- CASE
- Statistics
- 논문리뷰
- NLP
- nlp논문
- t분포
- update
- 자연어 논문 리뷰
- sql
- 그룹바이
- Window Function
- 설명의무
- 자연어처리
- SQL코테
- 자연어 논문
- torch
- GRU
- airflow
- 코딩테스트
- HackerRank
- sigmoid
- SQL 날짜 데이터
- inner join
- LSTM
- leetcode
- MySQL
- 짝수
- Today
- Total
HAZEL
[Basic Statistics : CH 10. 회귀분석] 단순 회귀분석, 다중 회귀분석 본문
CH10. 회귀분석
01 . 단순 회귀분석
001. 단순회귀분석 ( Simple regression analysis )
: 원인과 결과 관계를 파악하는 것.
: 하나의 변수가 다른 하나의 변수에 대해 미치는 영향을 파악하는 것
: 독립변수 X 가 종속변수 Y 에 미치는 영향을 회귀식 ( 회귀방정식 )을 이용하여 분석하는 방법
002. 독립변수와 종속변수
- 독립변수 ( dependent variable ) : X
: 어떤 연구나 조사를 수행할 때, 변수에 일어나는 현상을 설명하거나 , 원인이 되어서 다른 변수에 영향을 주는 변수
- 종속 변수 ( independent variable ) : Y
: 연구로 인해 설명이 되거나, 결과가 되는 것.
: 다른 변수로 부터 영향을 받는 변수
003. 자연과학 & 사회과학
1. 자연과학
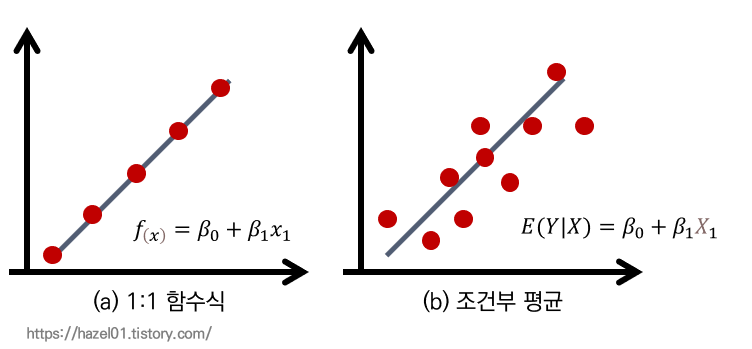
: 어떤 현상이 발생 했을 때, X의 변화가 Y의 변화에 영향을 주는 것이 1:1로 나타남.
: 모든 현상들이 거의 짝을 이루어 1:1로 발생함
: 1:1 함수식
2. 인문사회과학
: 인문사회과학에서는 변수가 굉장히 많음.
: 하나의 변수가 외부 변수들로 인해서 영향을 받기 때문에, Y에 영향을 줄 때 1:1로 주는 것이 아님
: 따라서 평균선을 그어서 회귀식을 만들어줌.
: 조건부 평균

004. 잔차 ( residual )
: 표본에서 나온 관측값이 회귀선과 비교해볼 때 나타나는 차이
: 실제 데이터를 측정하다보면, x에 따라서 y가 변화하는 차이가 다르게 나타남. 이러한 차이를 잔차라고 함
: 잔차는 최소한으로 줄여주는 것이 좋으나, 설명하지 못하는 것을 '잔차'라고 함

- 잔차는 특정한 변화값이 아니기 때문에, 패턴이나 규칙성이 나타나지는 않는다. 예측할 수 없다. 미지의 모수
[ 만약, 예측할 수 있다면, 베타2 라는 새로운 변수로 나타내야 함. - 즉 단순 회귀분석이 아니게 됨. ]
- 잔차가 작을 수록 회귀식을 잘 설명하고 있다고 생각하면 됨.
005. 최소자승법 (method of least squares ) 혹은 최소 제곱법
: 실제 데이터를 측정하다 보면 독립변수에 따라 종속변수의 변화하는 정도가 다르게 나타는 경우가 있는데, 이러한 개별 측정치들간의 차이
: 어떤 계의 해방정식을 근사적으로 구하는 방법으로, 근사적으로 구하려는 해와 실제 해의 오차의 제곱의 합이 최소가되는 해를 구하는 방법

자승 : 잔차의 제곱합을 최소로 하는 방법

- 잔차들을 다 더하면, + , - 가 되서, 0이 되기 때문에, 제곱을 한 후에 더해주는 것이다.
006. 최대우도법 (maximum likelihood method )
: 함수가 최대한 모수를 가지는 함수로 접근하는 것을 의미
: 우도 [ likelihood ] : 회귀식이 측정치를 잘 설명할 수 있도록 하는 가능성.
: 모수에 대한 설명력의 가능성을 최대한으로 올리는 것
: 모회귀식을 계속 쫒아가는 가능성
- 가능성에 대한 확률은 변화하면서, 회귀식을 계속 쫒아감.
: 즉, 모 회귀식을 아주 잘 설명할 수 있는 (우도) 가 커지도록 하는 방법
- 최소자승법과의 결과는 같지만, 보는 방향은 서로 반대방향이다.
007. 가우스 - 마코프 정리 ( Gauss - markov Theorem )
: 단순회귀 분석을 사용하기위해, 오차변수인 잔차가 갖추어야 할 네가지 조건.
* 5가지 조건을 만족한다면, BLUE( Best Linear Unbiased Esitimator ) 라고 부른다.
- BLUE : 최적화 되어있으면서도 선형이면서 취우쳐있지 않은 추정량.
1) 회귀모형은 모수에 대해 선형이 모형이다.
![]()
2) 오차항의 평균은 0 이다. ( 잔차에 대한 기댓값이 0 이다. )
3) 오차항은 모든 관측치에 대해 일정한 분산을 갖는다. ( 동분산 )
4) 서로 다른 관측치간의 오차항은 상관이없다. 즉, 공분산은 0이다.
5) 독립 변수는 랜덤하지 않다.
* 6) 번이 해당된다면, MVUE ( Minimum Varance Unbiased Estimator ) 라고 부른다.
6) 오차변수는 정규분포를 따른다.
008. 단순 회귀분석 계산하기.

009. 적합도 검정 ( goodness - of - fit test )
- 도출 된 회귀식이 얼마나, 표본 측정치를 설명하는지에 대한 검정
- 표본에 대한 회귀선의 설명력 ( R^2 )
: 회귀선이 추정치와 얼마나 일치하는지를 보는 것.
: 0 ~ 1 사이로 나타냄. ex, 0.98이면, 98%의 설명력을 가지고 있다고 말할 수 있음.



010. 분산분석
* 자유도
- SST 의 자유도 = n -1 / SSR 의 자유도 = 1 / SSE 의 자유도 = n - 2
- MSE = SSE / n -2
- MSR ( 평균회귀제곱 ) = SSR / 1
- F = ( SSR / 1 ) / (SSE / n-2 ) = MSR / MSE
ex, SST = 1950.933 / SSR = 1538.123 / SSE = 412.811 / R^2 = 0.788 / F = 48.438
- 왜 R^2를 구하는 것 일까?
: 회귀식의 설명력을 구하기 위해서
- 왜 F값을 구하는 것일까?
: 구한 이유는, 회귀식의 유의성을 검정하기 위해!!
설명력이 높아도, 유의하지않으면 아무 의미도 없기 때문에, F 값을 구하는 것이다.
011. 회귀식에 대한 가설 검정
ex, 연도별 광고비와 매출액을 기준으로 작성된 분산분석 결과이다. 이를 기반으로 회귀식이 유의한지 유의수준 0.05에서 검정하라.

1. 가설 수립
H0 : 회귀식은 유의하지 않다.
H1 : 회귀식은 유의하다.
2. F 분포표를 확인하기
F = 48.438
F( 1 , 13 ) = 4.67
: 자유도 1과 13일때의 값은 4.67 임.
-> F값인 48.438은 4.67인 임계치보다 큼.
-> 따라서, 귀무가설은 기각하고 대립가설을 채택한다.
-> 따라서 회귀식은 유의하다.
0012. 회귀계수의 유의성 검정


표본에서 도출한 회귀식이 의미를 가지는지, 아닌지를 판단. = 회귀식이 의미가 있는지 없는지.
1. 가설 수립
H0 : (β_0 ) ̂ = 0 H1 : (β_0 ) ̂ ≠ 0
H0 : (β_1 ) ̂ = 0 H1 : (β_1 ) ̂ ≠ 0
양측검정, -> 0.025 로 판단
2. (β_0 ) ̂ 와 (β_1 ) ̂ 의 검정 통계량 계산 - T 검정을 함.
** WHY ? 회귀계수는 T검정을 하는가 ?
A : 최승자승법을 이용해서 표본에서 회귀계수를 계산하게 된다.
이때, 표본에서 도출된 회귀계수는 표본의 구성에 따라서 변하게 된다.
여기서 나오는, 표본의 회귀계수에 대한 분포를 확인해야 하는데, 표본 잔차에서의 분산을 이용하게 됨.
모수를 알 수 있다면, Z 를 이용하지만, 그렇지 않으면 T 분포를 이용함,
T 분포는 자유도에 따라서 민감하게 움직인다. 여기서, 자유도는 n -2 다.
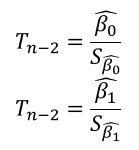

3. T 분포도를 확인하여, 임계치를 찾음
: 양측검정이므로, 0.025를 기준으로 판단.
자유도는 15 - 2 = 13임
| ± T_( 0.025 , 13 ) | = 2.1604
-> (β_0 ) ̂ 와 (β_1 ) ̂ 이 채택역에 모두 포함되어있지 않음.
-> 귀무가설을 기각하고 대립가설을 채택함.
-> 유의하다.
0013. 회귀계수의 신뢰구간
EX, (β_0 ) ̂ = 62.929 / (β_1 ) ̂ = 2.186인 회귀식 Y ̂=62.929+2.186X_i 에 대한 회귀계수 95%의 신뢰구간을 구하라.

02. 다중 회귀분석
001. 다중 회귀분석 ( multiple regression analysis )
: 종속변수에 영향을 미치는 독립변수가 여러 개인 경우에 실시하는 회귀분석


** 만약, y (종속변수)가 1개가 아니라, 여러개라면, 회귀식을 반복해서 써줘야한다. 복잡하당..
002. 다중회귀분석의 회귀계수 계산 - 최소자승법을 이용한다.

- 최소자승법을 이용하여 계산한다.
003. 적합도 검정
: 도출한 회귀식이 어느정도 측정치를 가지고 잘 설명하는 가?
: 다중회귀 분석에서 결정계수 자체가 회귀식의 '설명력'을 나타냄
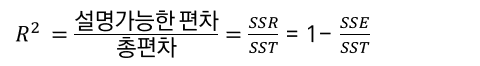
하지만, 다중회귀 분석은 단순회귀분석처럼 간단하지 않다!?
왜냐하면, 독립변수가 1개가 아니라 여러개이기 때문에, 회귀식이 종속변수에 대한 설명력이 늘어나게 된다.
( 모델링 할때도, 피쳐의 갯수를 늘리면, R^2이 상승하는 것을 볼 수 있다. 하지만 이렇게 회귀식을 설명하면 안된다! ㅠ)
= 독립변수의 수가 증가하면 따라서 커지는 증가함수이므로 독립변수가 유의하든 안하든 설명 변수에 의존적이다.
독립변수의 갯수가 늘어난 만큼, R의 변화를 수정해야한다!
이런 변화를 반영하는 것은 자유도를 기준으로 한다. 불편 추정량을 계산한다.
수정된 R^2 ( 결정계수 : adjusted R-squared ) 이라고 한다.
- 자유도로 판단한다.
004. 수정된 R^2(결정계수) 와 분산비율 F
- 수정된 결정계수 : 다변량 회귀분석에서는 독립변수의 수가 많아지면 결정계수(R^2)가 높아지므로 독립변수가 유의하든, 유의하지 않든 독립변수의 수가 많아지면 결정계수가 높아지는 단점이 있다! 따라서, 수정된 결정계수를 이용하는 것이다.

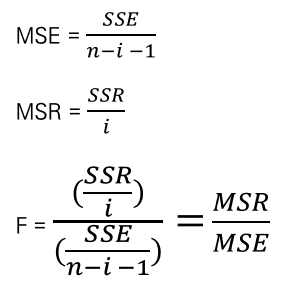
** 수정된 결정계수는 결정계수보다 항상 작은것이 특징이다!
005. 다중 회귀식의 유의성 검정
EX, 3가지 요인으로 외관, 편의성, 유용성에 대한 회귀분석을 실시했을 때, 유의수준 0.05에서 검정하라.

1. 가설 수립
H0 : 회귀식은 유의하지 않다.
H1 : 회귀식은 유의하다.
2. F 분포표를 확인하기
F = 15.084
F( 3 , 76 ) = 2.72
: 자유도 3과 76일때의 값은 2.72 임.
-> F값은 임계치 보다 크기 때문에, 귀무가설은 기각하고 대립가설은 채택한다.
즉, 회귀식은 유의하다!
006. 회귀계수의 신뢰구간
1. 가설 수립
H0 : (β_i ) ̂ = 0 H1 : (β_i ) ̂ ≠ 0
2. 신뢰구간
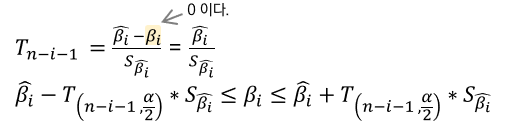
ex,


- 표 해석
1) 외관, 편의성, 유용성 변수들 모두 P 값이 0.05 보다 작으므로, 유효함을 알 수 있다.
2) Y절편의 경우 P값이 높은 경우가 있는데, 그냥 무시해도 된다고 한다.
공부 교재 : 제대로 시작하는 기초통계학
사회조사분석사
https://www.youtube.com/watch?v=jGOqkljySu8&list=PLsri7w6p16vuDN55ZGHVYnitXs2R1Wz6q
드디어,, 기초 통계가 끝났다..


