
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- t분포
- 표준편차
- nlp논문
- CASE
- leetcode
- Statistics
- 그룹바이
- 자연어 논문
- 자연어처리
- 코딩테스트
- sql
- airflow
- 설명의무
- MySQL
- 짝수
- NLP
- SQL코테
- 논문리뷰
- 자연어 논문 리뷰
- 카이제곱분포
- GRU
- SQL 날짜 데이터
- sigmoid
- Window Function
- update
- LSTM
- torch
- 서브쿼리
- inner join
- HackerRank
- Today
- Total
HAZEL
[ NLP : CH11. 신경망 기계번역 ] 제로샷 학습 ( zero-shot learning ) , 트랜스포머 본문
[ NLP : CH11. 신경망 기계번역 ] 제로샷 학습 ( zero-shot learning ) , 트랜스포머
Rmsid01 2021. 4. 26. 23:4511장. 신경망 기계번역
11.1. 다국어 신경망 번역
11.1.1. 제로샷 학습 ( zero-shot learning )
: 논문 - Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation Melvin Johnson∗ , Mike Schuster∗ , Quoc V. Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda Viégas, Martin Wattenberg, Greg Corrado, Macduff Hughes, Jeffrey Dean Google
www.aclweb.org/anthology/Q17-1024.pdf
* 특징
: 여러 언어 쌍의 병렬 코퍼스를 하나의 모델에 혼련하면 부가적으로 학습에 참여한 코퍼스에 존재하지 않는 언어쌍도 번역이 가능하다는 것
: 한번도 기계번역 모델에게 데이터를 보여주지 않아도 언어쌍 번역을 처리할 수 있음.
: 병렬 코퍼스에서 특정 언어쌍이 적은 경우에도 부가적인 효과를 발휘함.
* 구현 방법

: 기존 병렬 코퍼스의 맨 앞에 특수 토큰을 삽입하고 훈련함으로써 완성됨.
- 삽입된 토큰에 따라서 타깃 언어가 결정됨.
* 제로샷 학습 논문의 실험 목표
1. 다국어 신경망 머신러닝의 end2end 모델 구현
2. 서로 다른 언어쌍의 코퍼스를 활용하여 번역기의 모든 언어쌍에 대해 전체적인 성능을 올릴 수 있는지 확인
따라서, 4가지 관점으로 훈련
1. 다수의 언어 -> 하나의 언어 : 다수의 언어를 인코더에 넣어 훈련
2. 하나의 언어 -> 다수의 언어 : 다수의 언어를 디코더에 넣고 훈련
3. 다수의 언어 -> 다수의 언어 : 다수의 언어를 인코더와 디코더에 모두 넣고 훈련
4. 제로샷 번역 테스트 : 앞의 방법으로 훈련된 모델에서 훈련 코퍼스에 존재하지 않던 언어쌍의 번역 성능을 평가함.
-> 언어가 서로 다른 코퍼스로 합치다 보면, 분량이 다르므로 오버샘플링 기법의 사용 유무도 함께 실험함.
※ 오버 샘플링 : 양이 적은 코퍼스를 양이 많은 코퍼스와 비슷해지도록 데이터를 반복해 양을 늘려 맞춰주는 방법을 의미함
1] Many to One : 다수의 언어 -> 하나의 언어

: table 에서 보이는 single은 기존 방법, multi는 제안 방법이다.
: 전체적으로 성능이 향상된 것을 볼 수 있다. 실제 문제로 주어진 언어 데이터 이외에도, 동시에 훈련된 다른 언어의 데어터 셋을 통해 해당 언어의 번역 성능을 높이는 정보를 추가로 얻을 수 있음을 알 수 있다.
2] One to Many : 하나의 언어 -> 다수의 언어

: 이 실험에서는 single과 달리 multi의 성능이 향상되었다고 보기 힘들다.
: The model without oversampling achieves better results on the larger language compared to the smaller one as expected. ; 코퍼스의 양이 적은 영어/독일어 언어쌍 코퍼스는 오버샘플링의 이득을 본 반면, 양이 충분한 영어/프랑스어 언어쌍 코퍼스의 경우에는 손해를 보았다.
3] Many to Many : 다수의 언어 -> 다수의 언어

: 이 실험의 결과는 대부분 하락으로 이어짐.
4] Zero-Shop Translation : 제로샷 번역 테스트
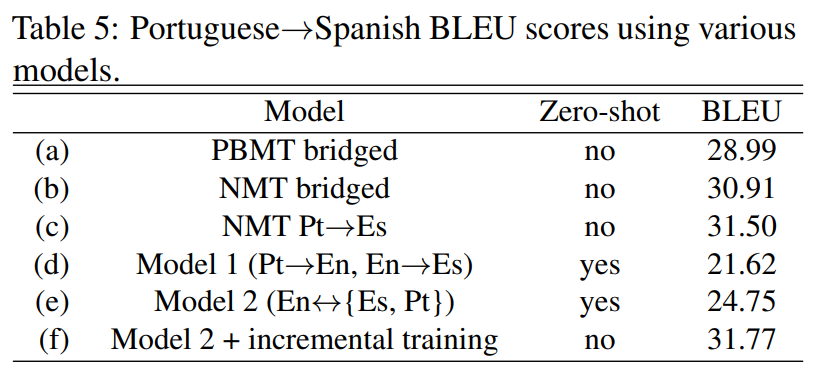
※ 브릿지 bridged : 중간 언어를 영어로 하여, 포르투갈어 -> 영어 -> 스페인어 와 같이 2단꼐에 걸쳐 번역을 진행.
※ PBMT ( Phrase-based machine translation ; 구문기반 기계번역 ) : 통계기반 기게번역 ( SMT ) 방식 중 하나
※ c : 단순 병렬 코퍼스를 활용하여 기존 방법대로 훈련한 베이스 라인
※ incremental training ( 점진 학습 방식 ) : c보다 적은 양의 병렬 코퍼스로 훈련한 기존 모델에 추가로 모델 2 방식으로 훈련한 모델
: MODEL1 과 MODEL2는 훈련 중에 포르투갈어 -> 스페인어 병럴 코퍼스를 알지 못했지만, BLEU가 20이 넘는다. 따라서, 병렬 코퍼스의 양이 얼마 되지 않을 경우 언어쌍의 번역기를 훈련할 때 이러한 방법을 통해 성능을 끌어올릴 수 있다.
: 특히, 한국어와 일본어 / 스페인어와 포르투갈어처럼 매우 비슷한 언어 쌍을 같은 소스 언어 또는 타깃 언어로 사용할 경우 그 효과는 증폭 된다.
11.1.2. 결론
다양한 언어쌍을 하나의 모델에 넣고 훈련하는 것은 트렌스포머와 같은 모델에 비하면 좋은 성능이아니다. 하지만, 다른 도메인의 데이터를 하나로 모아 번역기를 훈련시키는 과정에서 사용할 수 있다. 예를들어, 뉴스기사와 드라마 대본이 있다면, 문어체를 구어체로 바꾸는 모델을 만들 수도 있다. 이것은 두 언어 모델을 합치는 결합(보간)과 유사하다. 서로 다른 도메인의 코퍼스를 앞에서와 같은 방식으로 합쳐서 훈련한다면, 같은 언어쌍 훈련 데이터이므로 서로 다른 도메인의 코프서라고 해도 전체적인 성능 향상을 기대할 수있다.
--
트랜스포머는 추후에 추가할 예정



