
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- torch
- airflow
- sigmoid
- sql
- 그룹바이
- HackerRank
- MySQL
- Statistics
- 표준편차
- leetcode
- Window Function
- nlp논문
- t분포
- NLP
- 짝수
- 코딩테스트
- 자연어 논문 리뷰
- SQL코테
- inner join
- 논문리뷰
- SQL 날짜 데이터
- 자연어 논문
- 서브쿼리
- CASE
- 카이제곱분포
- update
- LSTM
- 설명의무
- 자연어처리
- GRU
- Today
- Total
HAZEL
[ NLP : CH10. 기계 번역 ] Teacher forcing, search ( greedy search , beam search ) , 성능 평가 ( PPL, BLEU ) 본문
[ NLP : CH10. 기계 번역 ] Teacher forcing, search ( greedy search , beam search ) , 성능 평가 ( PPL, BLEU )
Rmsid01 2021. 2. 21. 19:2410장. 기계 번역 ( machine translation : MT )
10.5. Teacher forcing
: 교사 강요 ( Teacher forcing ) : Target word를 디코더의 다음 입력으로 넣어주는 기법
※ 저번 10장 포스팅에서, 디코더 부분에서 teacher forcing 을 하는 것을 이야기 한 적이 있었다.
이번 포스팅에서는 조금 더 자세하게 다루도록 하겠다.
2021/02/17 - [DATA/NLP] - [ NLP : CH10. 기계 번역 ] seq2seq, attention , Input Feeding
[ NLP : CH10. 기계 번역 ] seq2seq, attention , Input Feeding
※ 미완성 : 추가적으로 학습한 후, 다시 정리하기. 10장. 기계 번역 ( machine translation : MT ) 10.1. 번역의 목표 : 문장이 주어졌을 때, 가능한 다른 언어의 번역 문장중 최대 확률을 갖는 문장을 찾아
hazel01.tistory.com
seq2seq은 훈련과정과 테스트 과정의 작동 방식이 다르다.
10.5.1. 자기회귀
Seq2seq 의 훈련방식과 추론 방식의 차이는 '자기회귀 ( AR : Autoregressive )' 라는 속성 때문에 발생한다.
자기회귀란 ?
: 과거의 자신의 값을 참조하여 현재의 값을 추론 ( 혹은 예측 ) 하는 특징을 가리킨다.

위의 수식과 같이 현재 time-step의 출력값은 인코더 입력 문장인 ( X ) 와 이전 time-step까지의 $ y_{<t} $ 를 조건부로 받아 결정된다. 즉, 과거 자신의 값을 참조하는 것을 말한다.
자귀회귀의 문제점 ?
: 이렇게 자귀회귀를 하다보면, 잘못 된 답이 출력값으로 나올경우, 다음 time-step에 잘못된 값이 입력값으로 주어지게 된다.
-> 그렇게 된다면, 시간이 지날 수록 더 크게 잘못 예측을 할 가능성이 생기는 것이다.
-> 즉, 문장( 또는 시퀀스) 의 구성이 바뀌거나 예층 문장(시퀀스)의 길이도 바뀌게 됨.
문제점을 해결하는 방법 ?
: 학습과정에서는 이미 정답을 알고 있기 때문에, 이전 time-step의 출력값을 인풋으로 넣는 것이아니라, 정답을 input으로 넣어준다!
즉, 교사강요를 하는 이유는!
훈련과정에서 다음 단어를 잘 예측한다면, 상관 없지만 이전 시점의 디코더 셀의 예측이 틀렸는데, 그것을 현재 시점의 디코더 입력을 사용하면, 예측이 잘못될 가능성이 커진다. 이것의 연쇄 작용으로 디코더 전체의 예측을 어렵게 하고 훈련 속도 저하의 원인이 된다. 따라서, 강제로 교육하는 방법을 사용하는 것이다!
10.5.2. teacher forcing 훈련 방법
아래 정답 : " 나는 라이언을 좋아해 " 이다.
teacher forcing을 안하면, 잘못된 답 ( ex, 꽃을 ) 이 다음의 input 으로 들어간것을 볼 수 있다.
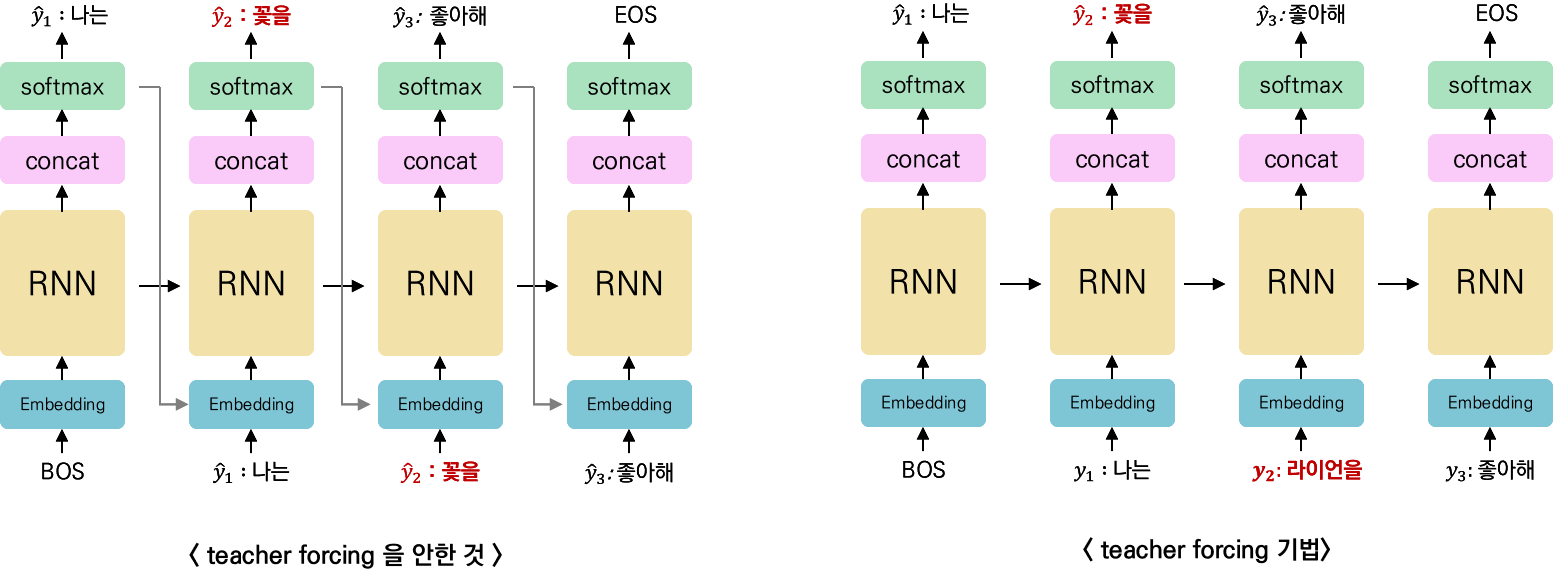
1) 훈련과정 : 디코더에게 인코더가 보낸 컨텍스트 벡터와 실제 정답을 입력 받았을 때, 실제 정답을 알려주면서 훈련하는 것이다.
2) 테스트 과정 : 추론할 때는, 정답 Y를 모르기때문에, 오직 context vector와 <sos> ( bos ) 만으로 다음에 올 단어를 예측하고, 그 단어를 다음 시점의 셀의 입력으로 넣는 행위를 반복한다.
- 장점 : 학습이 빠르다.
: 인풋에 대해 정답을 알기 때문에, input을 한번에 넣어 줄 수있다.
즉, 모든 time-step에 대해서 한번에 계산할 수 있다는 것이다.
- 단점 : 노출 편향 문제 ( exposure bias problem )
: 추론 과정에서는 실제값을 제공할 수 없어, 자기 자신의 출력값을 기반으로만 예측을 이어가야한다.
즉, 학습과 테스트 단계 사이의 차이가 존재하여 모델의 안정성을 감소시킬 수 있다.
그러나, 이러한 문제가 생각만큼 큰 영향을 미치지 않는다는 연구 결과가 나와 있다고 한다.
(T. He, J. Zhang, Z. Zhou, and J. Glass. Quantifying Exposure Bias for Neural Language Generation (2019), arXiv.)
※ 만약 input feeding 을 추가한 모델이라면, 모든 time-step을 한번에 계산하는 것은 불가능 하다.
그래서, decoder를 훈련시킬때 , input feeding 이 추가했는지 안했는지에 따라서 수식(코드) 등이 바뀌게 된다!

10.6. 탐색 ( search , 추론 )
: X와 Y를 모두 알고있는 상황이 아닌, X 만 주어진 상태에서 $ \hat{Y} $ 을 추론(예측)하는 방법
탐색이라고 부르는 이유는 '탐색 알고리즘'에 기반하기 때문이며,
단어들 사이에서 최고의 확률을 갖는 경로를 찾는것이 목적이다.
10.6.1 샘플링
: 각 Time-step별 $ \hat{y} _t $ 를 고를 때 마지막 소프트 맥스 계층에서의 확률 분포대로 샘플링 하는 것. 그리고 다음 time-step에서도 샘플링을 반복하면서, EOS가 나올때까지 하는 것을 말함
-> P(X{Y)에 가장 가까운 형태의 번역이 완성됨 하지만, 입력에 대해 매번 다른 출력 결과물을 만들어 내는 단점이 있다.
$$ \hat{y} _t \sim P(y_t | X, \hat{y}_{<t};\Theta ) $$
10.6.2. 탐욕 탐색 알고리즘 ( 그리디 탐색 )
: 소프트 맥스 계층에서 가장 확률값이 큰 인덱스를 뽑아 해당 time-step의 $ \hat{y} _t $ 로 사용하는 것
: 전체 문장의 확률값을 보는 것이 아니라, 현재 time-step 에서 가장 좋아 보이는 것을 그때 그때 선택하는 것
ex, 예측하고 싶은 것 < 나는 허브티를 혼자 마시는 것을 좋아해 >
< 나는 허브티를 것을 > 와 같이 잘못 예측됬다면?
단점 :
잘 못 예측된 결과를 바탕으로 뒤에서 또 추론을 하는데, 그렇다면 더더 에러가 커진다.
이상한 답인 것을 알면서도 뒤로 돌아갈 수 없다 → 최적의 예측문제를 해결할 수 없다.
$$ \hat{y}_t = argmax P(y_t | X, \hat{y}_{<t};\Theta ) $$
10.6.3. 완전 탐색 ( exhaustive search , 브루트 포스(Brute-Force) )
: 현재 time- step만 보는 것이 아니라, 매 타임에 대해 가능한 모든 경우를 따지는 것
$ P(y|x) = P(y_1|x)P(y2|y1,x)...P(y_t|y1...y_{t-1},x) = \prod ^t _1 P(y_t|y1...y_{t-1},x) $
단점 :
time step t까지의 가능한 모든경우를 따진다면, 매 타임스텝마다. 단어의 수( vocab size : v ) 가
기하 급수로 늘어난다. 이것을 계산하는것은 한계가 있다.
10.6.4. 빔서치
: 그리디탐색과 완전탐색에 대한 중간 단계
단 하나의 candidate뿐만아니라, $ v^t $ 승에 대해서 모두 구하는게 아니라 가능한 k개의 경우에 수를 유지하고,
디코딩을 진행하고 k개의 후보자에 대해서 가장 높은 확률을 택하는 것.
K = beam size 를 의미함 < 보통 5~10 이라고 함, 어떤 논문에서는 5이상 늘리면 성능이 급격히 감소한다고 함 >
- 누적확률을 사용하여 최고 순위 k개를 뽑는다. 이때, 보통 로그 확률을 이용하여 현재 time-step까지의 로그 확률에 대한 합을 추적한다.
- 이전 time-step에서 뽑힌 k 개에 대해 계산한 현재 time-step의 모든 결과물 중에서 최고 누적확률 k개를 다시 뽑는다.
- 확률값은 항상 마이너스(-)로 나오게 된다. 그 중에서 더 큰 값을 가지는 k가 큰 확률을 가진다고 볼 수 있다.
- 반복적으로 2개를 뽑는데, 생성을 끝내는 시점은 모델이 end token을 해당 단어가 예측 할 때이다.

1) 빔서치는 언제까지 진행 하나 ?
1. 직접 정한 t라는 타임 스텝이 접근 했을 경우
2. 임시 공간에 저장해둔 ( 완료된 가설 ) 이 n개 만큼 저장 되었을 경우
-> 완료된 가설의 리스트는 임시 공간에 저장되는데, 이 중에서 높은 score를 가진 값을 최종적으로 뽑음.
2) 빔서치의 장점
1. 더 넓은 경로에 대해 탐색을 수행하므로, 더 나은 성능을 보장함
2, globally optimal solution을 보장하진 않지만, 완전 탐색보다는 효율적이다.
3) 빔서치의 단점
1. 빔의 크기만큼 번역을 더 수행해야하므로 속도 저하가 발생함
-> 병렬 수행하여 문제 해결 ( 미니 배치 만들어 수행 )
2. time – step까지의 확률을 모두 곱 ( 로그확률 : 합 ) 하므로 , 문장의 길이가 길어질수록 확률이 낮아짐
즉, 문장이 짧을 수록 더 높은 점수를 획득
-> 길이 패널티 를 사용하여 해결
※ 병렬 작업 ( 미니 배치 )
: 매 time-step마다 임시로 기존의 미니배치에 k배가 곱해진 미니 배치를 만들어 수행
( 그러나, 속도 저하가 전혀 없지는 않다. )

※ 길이 페널티 ( length penalty )
: 예측된 문장의 길에 따른 페널티를 주어 짧은 문장이 긴 문장을 제치고 선택되는 것을 방지.
1) 2개의 하이퍼파라미터가 필요 : 보통 이것은 추가 튜닝의 여지가 있지만, α=1.2 β=5 의 값을 가짐

2) 단순하게, 가설별로 단어의 갯수를 나누어주어 normalize 를 해준다.

10.7. 성능평가
: 번역기의 성능을 평가하는 방법으로 1) 정성적 평가 2) 정량적 평가 방식 이 있다.
10.7.1. 정성적 평가 ( intrinsic evaluation )
: 보통 사람이 번역된 문장을 채점하는 형태 -> 정확하지만 자원과 시간이 많이든다.
10.7.2. 정량적 평가 ( extrinsic evaluation )
: 단순히 기존의 신경망 훈련시의 목적함수 값이나 손실함수 값을 사용할 수 있지만, 언어적 특징이 반영된 평가 방법이 훨씬 더 정확함.
1. PPL ( Perplecity )
: 매 time-step마다 최고 확률을 갖는 단어를 선택(분류) 하는 작업 – 교차 엔트로피를 손실 함수로 사용.
: 교차 엔트로피 손실값에 exp를 취하여 PPL값을 얻음
-PPL은 수치가 ‘낮을 수록‘ 좋은 성능을 가졌다는 것을 의미함
-PPL을 최소화 한다는 것은 문장의 확률을 최대화 하는 것
장점 : 손실함수 교차 엔트로피와 직결되어 바로 알 수 있다.
단점 : 실제 번역기의 성능과 완벽한 비례관계라고 할 수 없다.
왜냐하면, 각 time-step별 실제 정답에 해당하는 단어의 확률만 채점하기 때문.
-> 어순이 바뀌고 비슷한 어휘로 치환되도 틀린번역은 아님. => 번역 품질과 크로스엔트로피 사이에 괴리가 있음
2. BLEU ( Bilingual Evaluation Understudy )
: 정답문장과 예측문장 사이에 일치하는 n-gram 개수의 비율의 기하평균에 따라 점수가 매겨짐. -> 높을 수록 좋음
1) 정밀도, 재현율, F - measure 의 개념과 문제점
- 정밀도( precision ) : 예측된 문장에서 실제로 맞춘 비율
- 재현율 ( recall ) : 실제 문장에서 실제로 맞춘 비율
- F – measure = (precision ×recall ) / (1/2(precision+recall))
: 재현율과 정말도의 조화 평균 , 값을 구할 때 작은 값에 더 큰 가중치를 줌

즉, 단순히 정밀도 재현율 F-measure을 이용하면, 문장의 순서가 달라도 그 단어만 같다면 예측율이 높아진다.
언어 번역에서는 이러한 부분이 문제가 된다.
2) BLEU ( Bilingual Evaluation Understudy )

※ 간결도 패널티
: 예측된 번역문이 정답 문장보다 짧을 경우, 점수가 좋아지는 것을 방지하는 것이다.
: 정밀도에 대한 기하평균은 recall에 대한 반영이 없기 때문에, 문장이 얼마나 짧게 예측된지 모름 따라서 패널티를 부여하는 것이다.
만약, 원래 문장보다 더 긴 길이의 문장이 예측된다면, 이것은 원래 문장에서의 단어가 빠짐없이 소환되었다고 가정한다. 즉, recall = 100 이라고 가정한다.
그렇기 때문에, 더 긴 길이의 문장에 예측되더라도 1의 값을 가지도록 한다.
** 본 게시글은 아래 자연어 책을 공부하면서 작성하였습니다.
출처 : 김기현의 자연어 처리 딥러닝 캠프 _ 파이 토치 편
** 책에서 간단하게 넘어간 내용은, 아래 글들을 참고하였습니다.
https://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture08-nmt.pdf
m.blog.naver.com/sooftware/221790750668



