
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- SQL코테
- 자연어처리
- t분포
- GRU
- 표준편차
- HackerRank
- Window Function
- 서브쿼리
- leetcode
- Statistics
- SQL 날짜 데이터
- 그룹바이
- sql
- CASE
- MySQL
- inner join
- 논문리뷰
- torch
- sigmoid
- 카이제곱분포
- 자연어 논문 리뷰
- airflow
- nlp논문
- 자연어 논문
- 짝수
- LSTM
- NLP
- 설명의무
- update
- 코딩테스트
- Today
- Total
HAZEL
[Deep Learning 03 ] GRU ( Gated Recurrent Unit ) 본문
Deep Learning 03. GRU ( Gated Recurrent Unit )
1. Vanilla RNN vs LSTM vs GRU ( Gated Recurrent Unit )
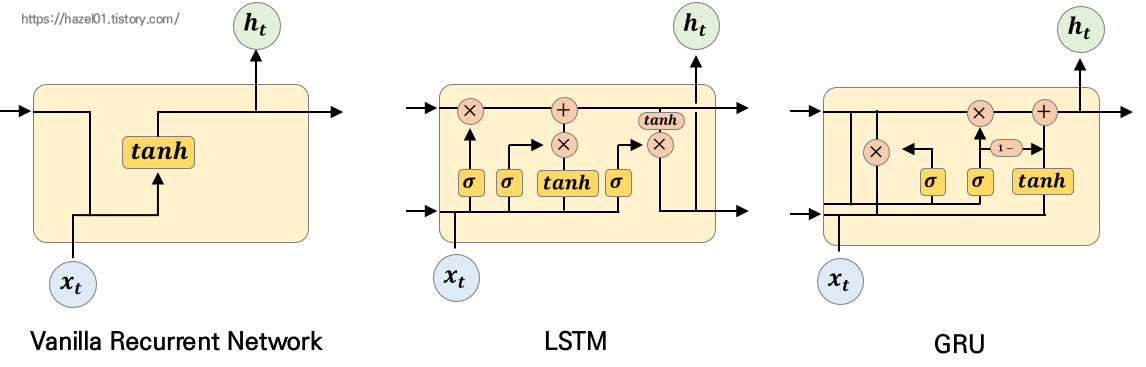
Vanilla RNN은 왼쪽의 모형처럼 단순하게 생겼다. 그에 비해 LSTM은 굉장히 복잡한 모형으로 생겼다.
GRU는 LSTM의 기능을 가졌지만, 단순화 시킨 모습을 가지고 있다.
2. GRU ( Gated Recurrent Unit )의 구조
: GRU는 Cell State가 없고, Hidden State만 존재하는 구조이다.
: Forget Gate 와 Input Gate가 결합되어있다.
: Reset Gate가 추가되어있다.

- Reset Gate : 이전 Hidden state를 얼마나 사용할지 정하는 역할. 즉, 새로운 feature을 뽑을 때, 얼마나 가져오는지 정하는 것 . Sigmoid 활성함수로 0~1의 값을 가짐. 0에 가까운 값이 되면 ‘Reset’이 된다.
- Forget Gate : hidden state와 input에 활성함수(sigmoid)를 지나친다. 그 결과(0~1)를 곱해서 얼마나 잊을지를 결정해준다. LSTM과 동일하게 Forget Gate를 사용한다. Gru의 gorget gate는 lstm의 forget gate와 output gate를 겸한다.
- Input Gate : Forget Gate를 1에서 빼서 Input Gate로 사용한다. 잊은 것을 다시 채우는 느낌이다.
- hidden state : Reset gate,Forget Gate를 모두 적용하여 계산한 것. LSTM의 Cell state와 hidden state역할을 겸한다.
3. GRU ( Gated Recurrent Unit )의 코드
RNN과 LSTM을 구현한 것처럼
Tensorflow - 2.2.0 의 keras를 통해서 구현한 코드 중
tf.keras.layer : 이 함수 안에 GRU 를 입력하면 바로된다.
class Gru(tf.keras.Model):
def __init__(self):
super(MyModel, self).__init__()
self.emb = tf.keras.layers.Embedding(NUM_WORDS, 16)
self.rnn = tf.keras.layers.GRU(32)
self.dense = tf.keras.layers.Dense(2, activation = 'softmax')
def call(self, x , training = None, mask = None):
x = self.emb(x)
x = self.rnn(x)
return self.dense(x)


