
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- HackerRank
- 짝수
- sigmoid
- 설명의무
- LSTM
- torch
- CASE
- 표준편차
- sql
- update
- 카이제곱분포
- t분포
- inner join
- SQL 날짜 데이터
- NLP
- 자연어 논문 리뷰
- airflow
- 논문리뷰
- 서브쿼리
- leetcode
- 자연어 논문
- nlp논문
- 코딩테스트
- 그룹바이
- GRU
- Window Function
- Statistics
- MySQL
- 자연어처리
- SQL코테
- Today
- Total
HAZEL
[Deep Learning 01 ] 순환 신경망(Recurrent Neural Network, RNN) / 순차데이터(Sequential Data) / Vanilla Recurrent Network 본문
[Deep Learning 01 ] 순환 신경망(Recurrent Neural Network, RNN) / 순차데이터(Sequential Data) / Vanilla Recurrent Network
Rmsid01 2020. 12. 20. 00:54Deep Learning 01.
1. 순차 데이터 ( Sequential Data )
001. 순차데이터의 개념
순차데이터 ( Sequential Data ) : 순서가 의미가 있으며, 순서가 달라지는 경우 의미가 손상되는 데이터를 의미한다.
순차 데이터 중에서,
Temporal Sequence 는 시간적 의미가 있는 것을 의미한다.
그것이 일정한 시간차라면 Time Series 라고 한다.
002. 순차데이터의 Resampling
Resampling 이란, Temporal Sequence를 Time Series로 변환하기 위해 수행하는 것이다.
resampling을 수행하는 방법으로
1) 데이터를 보간(Interpolation)한다. 즉, 데이터를 추정하여 비어있는 시간의 사이사이를 매꾸는 작업을 한다.
2) 균일 시간 간격으로 다시 샘플링을 한다. 즉, 일정한 시간으로 다시 샘플을 추출하는 일을 수행하는 것이다.
왜? resampling 작업을 하는 것일까?
=> 보통 Temporal Sequence로 데이터를 얻게 될 가능성이 높다. 하지만, time series로 변경하는것이 더 효과적인 결과를 얻어낼수있기 때문에 resampling작업을 하는 것이다.
003. 순차데이터를 처리하기 위해서 DNN 을 사용하면 어떻게 될까?
순서의 의미가 있는 순차데이터를 DNN으로 그냥 처리하면 문제가 발생한다.
( 그래서, 이러한 시계열 데이터는 DNN이 아니라 RNN을 사용하는 것이다! )
1) 입력 문제 발생
: 순차데이터는 입력데는 길이가 매번 다르다. 따라서, 그냥 입력으로 넣었을 때, 처리하기가 까다롭다
2) 출력 데이터 문제
: 결과가 될 수 있는 경우의 수가 많은데 그걸 DNN이 표현해줄 수 없다.
-> 이러한 문제를 해결하기 위해서, 시퀀스 길이에도 상관없이 인풋과 아웃풋을 받아들일 수 있는 네트워크 구조인 RNN을 쓰는 것이다.
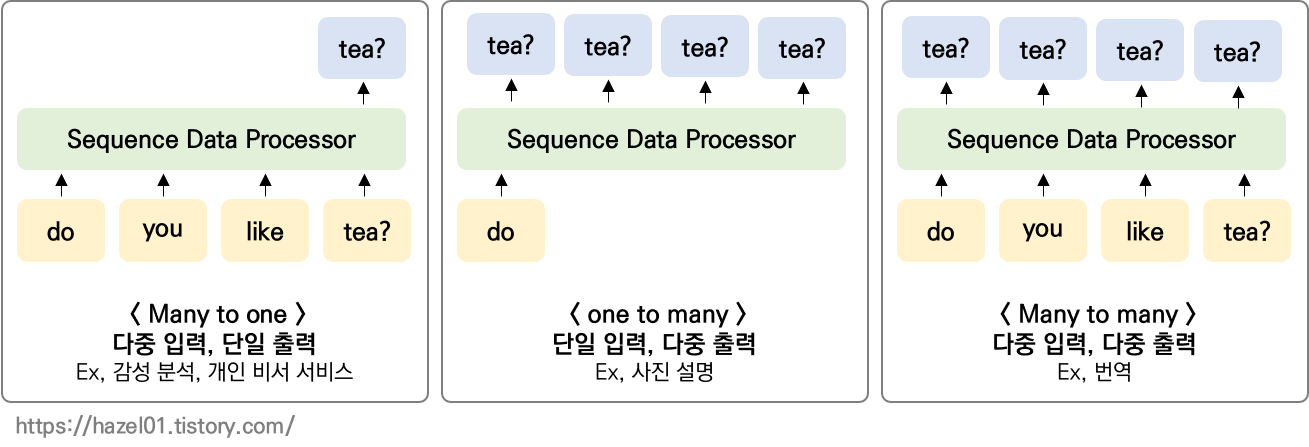
004. 순차데이터의 종류
005. 기억 시스템 ( Memory System )
: 한마디로 표현하자면! ' 모든 입력을 다 참고하는 것 '
내가 원하는 결과를 내려면, 즉 원하는 대답을 하려면 한개의 입력이 아니라 전체의 내용을 다 기억할 수 있어야 한다.

: 기억 시스템과 반대인 무기억 시스템(Memoryless System)은 기억을 하지 않는 시스템이다.
즉, 입력이 들어올 때마다, 동작 구조를 바꾸지 않는 것을 의미한다. 예를 들어 CNN, DNN , shallow NN 등이 있다.
다시말하면! DNN 은 무기억 시스템이기 때문에 시계열 데이터의 성질을 받아드리지 못하는 것이다!
2. 기본적인 순환 신경망 ( Vanilla Recurrent Network )
얕은 순환신경망을 Vanilla Recurrent Network라고 한다.
Shallow NN 과 Vanilla Recurrent Network을 비교하면서 개념을 정리하려고 한다.
001. Shallow NN(얕은 신경망)은?
: hidden layer 가 한개인 단층으로 구성된 neural network이다.
위에서 언급한 것 처럼 '비메모리 시스템'이다.
무기억 시스템이기 때문에, n번째의 스텝이 n+1번째의 스텝에 영향을 주지 않는다.
다시말하면, n-1 혹은 n-2번째의 결과가 n번째의 입력에 영향을 받지 않는다는 것이다.
002. Vanilla Recurrent Network 는?
Vanilla Recurrent Network는 메모리 시스템이다.
즉! n-1의 결과가 n의 입력에 영향을 준다는 것이다.

위의 그림을 보면, shallow NN 은 입력부분에 X 한개만 들어가지만, Vanilla Recurrent Network에는 n-1째 히든 레이어가 들어가 있다. < 얕은 신경망 구조에 순환이 추가된것! >
수식에도 굉장히 직관적으로 그것이 표현된 것을 알 수 있다.
n-1 째 히든 레이어가 추가된다는 점은! RNN 모델에서 굉장히 중요한 부분이다.
입력에 H_n-1 ( n-1스텝의 히든레이어)를 가져온 후 , concatnation을 해주어 자연스럽게 입력의 길이가 길어진다.
* n 번째 출력에는 n-1의 영향을 받는다. n-1은? n-2영향을 받았던 것이다. ,,, 즉 n번째는 1번부터 n-1의 영향을 모두 받은 것이다. " RNN 출력은 이전 모든 입력에 영향을 받는다 "
* activation 은 tanh을 사용함
3. 다중 계층 순환 신경망 ( Multi - Layer RNN )
Deep NN 처럼, RNN 또한 hidden layer 을 더 쌓아서 만들 수 있다.

하지만, 다중 계층 순환 신경망은 신경망이 복잡해져서 학습이 잘 되지 않는다.
일반적으로 dnn은 한방향(Depth)으로만 gradient가 타고 가면 되지만, RNN은 TIME-STEP을 여러번 밟기 떄문에
Depth x sequence 만큼 gradient가 뚫어야한다.. ! 즉! 매우매우매우 복잡해진다는 의미이다.
따라서 다중 계층 순환 신경망은 잘 사용하지 않는다.
4. 기울기 소실 문제
위에서 살짝 언급한 문제를 다시 이미지로 확인해보면 이렇게 나타난다.
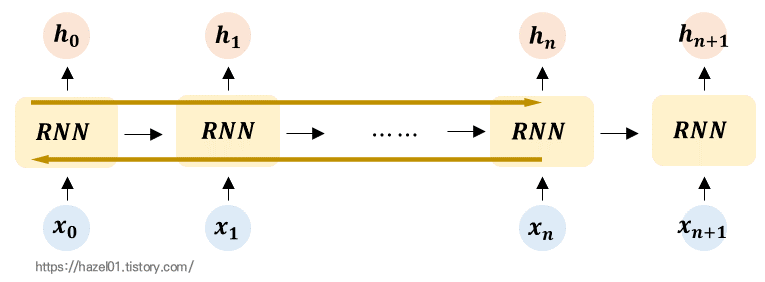
어떤 입력정보가 x0 이고 출력이 hn에 나온다고하면, 시점의 길이가 매우 커지게 된다.
이렇게 되면, 학습능력이 떨어진다. 왜냐하면, hn의 출력을 내기 위해서는 hn부터 x0까지 다 타고 가서(갈색 화살표) x0의 정보를 가져와야 하기 때문이다. 즉, 역전파가 이루어질때, 이렇게 깊이 따라가면 기울기 소실문제가 발생하게 된다.
: 입력정보가 사용되는 출력의 시점과 차이가 많이 날 경우, 학습능력이 저하되게 된다.
이러한 Vanilla Recurrent Network 의 단점을 해결하기 위해서 LSTM 등의 모델이 등장하게 됬다.
다음 포스팅은 LSTM ! ( 두둥, , )
5. Vanilla Recurrent Network 의 CODE
class Vnn(tf.keras.Model):
def __init__(self):
super(MyModel, self).__init__()
self.emb = tf.keras.layers.Embedding(NUM_WORDS, 16)
# 원핫 벡터가 10000일때, 첫번째가 MY 였다면, 특정 단어들이 원핫 벡터들이 하나씩 표현됨.
# Embedding : 원핫 벡터는 정수값이라서, 심지어 0,1의 바이너리값이여서, 실수값을 가져오기 위해서 길이가 10000인 원핫 벡터를 길이가 16인 피쳐 벡터로 바꿔주는 역할을 함
self.rnn = tf.keras.layers.SimpleRNN(32) # rnn layer를 사용하는데, 심플하게 바닐라 rnn사용
self.dense = tf.keras.layers.Dense(2, activation = 'softmax')
def call(self, x , training = None, mask = None):
x = self.emb(x)
x = self.rnn(x)
return self.dense(x)
'DATA ANALYSIS > ML & DL' 카테고리의 다른 글
| [ PyTorch 01. ] Basic, Operations, View, Slice and Index, Compile, AutoGrad (0) | 2021.04.29 |
|---|---|
| [ Deep Learning 02 ] 경사하강 학습법 ( Gradient Descent ) , 옵티 마이저 ( Optimizer ) (0) | 2021.01.27 |
| [Deep Learning 01 ] 얕은 신경망의 구조 ( Shallow Neural Network ) (0) | 2021.01.22 |
| [Deep Learning 03 ] GRU ( Gated Recurrent Unit ) (0) | 2020.12.26 |
| [Deep Learning 02 ] LSTM ( Long Short - Term Memory ) (0) | 2020.12.21 |



