
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- GRU
- torch
- Window Function
- sql
- t분포
- 그룹바이
- inner join
- nlp논문
- HackerRank
- update
- leetcode
- NLP
- 카이제곱분포
- 자연어 논문 리뷰
- sigmoid
- airflow
- Statistics
- 코딩테스트
- 자연어 논문
- SQL 날짜 데이터
- 표준편차
- 서브쿼리
- 자연어처리
- MySQL
- LSTM
- 설명의무
- 논문리뷰
- 짝수
- SQL코테
- CASE
- Today
- Total
HAZEL
[Basic Statistics : CH 5. 추정] 점추정과 구간추정 , 모평균의 구간 추정, 모집단 비율 및 분산의 구간추정 본문
[Basic Statistics : CH 5. 추정] 점추정과 구간추정 , 모평균의 구간 추정, 모집단 비율 및 분산의 구간추정
Rmsid01 2020. 12. 1. 13:38CH5. 추정
01 . 점추정과 구간추정
001. 점추정 ( point estimation )
- 점추정 : 모수를 특정한 수치로 표현하는 것 ex, 30분
- 하나의 값으로 표현하는 것이기 때문에, 틀릴 확률이 多
- 추정량을 통해 모수를 추정
002. 추정치와 추정량
1. 추정치 ( estimate )
: 모수를 추정하기 위해 선택된 표본을 대상으로 구체적으로 도출된 통계량
2. 추정량 ( estimator )
: 표본에서 관찰된 값으로 추정치를 계산하기 위한 도출 함수
003. 바람직한 점 추정량 조건
1. 평균 오차제곱
: 평균 오차 제곱이 최솟값이어야 한다.
- 오차 ( 평균 - 측정치 )의 평균이 최소가 되어야 하는 것 = 평균에 가깝다 와 같은 의미
2. 불편성
: 추정량이 모수와 같아야 한다.
- 불편 추정량 : 편중되지 않고 모수와 같은 것
3. 일치성
: 표본의 크기가 모집단 규모에 근접해야 한다.
- 표본의 크기가 모집단에 근접할수록, 오차가 줄어듦.
- 표본의 개수가 되는 n이 무한대로 간다면, 표본이 모수가 됨.
4. 유효성
: 추정량의 분산이 최솟값이어야 한다.
- 추정 값의 분산 ( 흩어진 정도 )가 최솟값이 되어야 한다.
5. 충분성
: 표본이 모집단의 대표성을 가져야 한다.
- 표본을 추출할 때, 과학적으로 추출해야 한다.
- 추출된 표본은 모집단을 충분히 설명할 수 있는 것 이어야 한다.
** 1번 ~ 4번은 바람직한 점추정만 해당하는것.
** 5번은 점추정 뿐만 아니라, 통계학 전체에 해당하는 통계량에 대한 조건
004. 구간 추정 ( interval estimation )
- 구간 추정 : 모수를 최솟값과 최댓값의 범위로 추정하는 것
: 일정 신뢰수준 하에서 모수를 포함할 것으로 예상되는 구간을 제시
: 신뢰수준과 구간의 길이는 반비례
ex, 25분 ~ 35분 -> 범위로 나타내는 것
- 구간 추정을 사용하는 이유
: 조사자의 입장에서는 오차를 줄이기 위해 점추정 대신 신뢰도를 제시하면서 상한 값과 하한값으로 모수를 추정하는 구간추정을 사용함
005. 신뢰구간 ( confidence intervall ; CI )
: 상한값과 하한 값의 구간으로 표시되며, 신뢰 수준을 기준으로 추정된 점으로부터 음(-)의 방향과 양(+)의 방향으로 하한과 상한을 표시
: 신뢰구간은 모수가 실제로 포함될 것으로 예측되는 범위이며, 모집단 실제 평균값이 포함될 확률을 'CI의 신뢰 수준'이라고 함.
- 신뢰도가 낮으면, 구간(범위)이 좁아짐.
- 신뢰도가 높으면, 구간(범위)가 넓어짐.
- 신뢰도 100%!? - 신뢰도 100%이면, 최상의 결과이지만, 신뢰도가 올라갈수록 구간은 넓어진다. 즉 z 값이 무한대임을 의미한다. 틀릴 확률은 0% 이지만, 이것은 전혀 의미가 없다. 따라서 약간의 신뢰도를 포기하고 유의미한 구간을 확인하는 것이 유용하다.


02. 모평균의 구간 추정
001. 모집단의 표준편차를 아는 경우 -> 표준 오차를 이용하여 구간 추정
- 사실, 모집단의 표준편차를 아는 경우는.. 거의 없다.

ex, 표본수 : 200 / 평균 : 30,000 / 모평균 편차 : 500 / 95%의 신뢰 수준으로 모평균의 신뢰구간 추정하면?
=> 30,0000 - 1.96 * 500/ √200 ≤ m ≤ 30,0000 + 1.96 * 500/√200
** 표준편차 vs 표준오차
: 모집단에서 표본 100개를 추출한 후, 평균을 추정하는 실험을 할 때, 추출한 100개의 표본에 대한 평균을 구한 후 분포까지 확인해야 표본의 특성을 더 정확하게 파악할 수 있다. 분포를 표현하는 방법은 표준편차(standard deviation)와 표준오차(standard error)가 있다.
- 표본 편차 : 표본으로부터 얻어내는 분산에 제곱근을 씌운 것
- 표준 오차 (SE / σ/√n )
: 표본의 추출 횟수를 늘린 후, 편차를 구한 것. 표준 편차가 여러 개가 나옴. 그것을 기준으로 하는 오차
002. 모집단의 표준편차를 모르는 경우 -> 표본의 표준편차를 이용하여 구간 추정
- 모집단의 표준편차를 안다면, 위의 공식에 대입하면 된다.
- 하지만, 대부분의 경우 모집단의 표준 편차를 모른다.
=> 그럴 경우, 표본의 표준편차를 이용하여 신뢰구간을 추정
- 모집단 ( σ ) / 표본 ( s )라고 표현
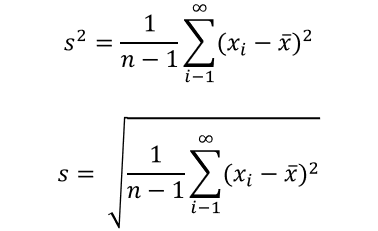
- 이렇게 표본의 표준편차를 이용해서 구한 신뢰구간은 모 표준편차를 통해 구한 신뢰구간보다 틀릴 가능성이 더 크다.
: 즉, 신뢰구간의 범위가 더 커질 수밖에 없음
: 따라서, Z 분포가 아닌 T 분포를 이용함.
- T 분포는 모수를 알지 못하는 상황에서 정규분포를 이용하는 모집단에서 추출한 표본의 크기가 작을 때 이용하는 분포 즉, T 분포는 자유도에 따라서 다른 분포를 가짐
- 자유도가 낮다는 것 = 표본의 개수가 낮다.
- 자유도가 높아질수록, 표준 정규분포와 같다.
: 자유도가 높아지면 ( 표본의 개수가 충분히 높으면 ) 표준 정규분포와 근사한 값을 가짐 ( 중심 극한 정리 )

003. 표본의 크기 결정
- 표본의 크기가 커진다 = 통계량에 대한 신뢰도가 높아진다.
- 표본의 크기가 작아진다 = 모집단을 대표하는 신뢰도가 떨어진다.
- 적절한 표본의 크기란?
* 모수들의 신뢰구간 추정 시 1 - α 를 지나치게 넓히는 것은 모수 추정에 좋지 않음
* 신뢰구간을 구할 수 있는 신뢰 수준 ( 1 - α )를 결정
* 측정할 모수에 따라 추정 오차의 한계 크기 결정

- 예시 문제,
1) 표준편차를 아는 경우 : 표본의 개수를 구하기 ( 신뢰 수준 99% , 허용오차 ±100ml , 표준편차 150 ml )
: 1 - α = 0.99 , z = 2.58, 허용오차 = 100, 표준 편차 = 150
n = [ (2.58 * 150 ) / 2=100 ] ^2 = 14.9769 => 약 15개
2) 표준편차를 모르는 경우 : 10번의 표본 추출 -> 표준편차 = 170ml, 신뢰수준 99% , 허용오차 ± 100ml 표본 개수 구하기
: 1 - α : 0. 99 , z_(α/2) = 2.58, 허용 , 허용오차 = 100 , 표준편차 = 170
n = [ ( 2.58 * 170 ) / 100 ]^2 = 19.2390 => 약 20개
03. 모집단 비율 및 분산의 구간 추정
001. 모집단 비율의 구간
- 모비율 ( P ) : 모집단에서 어떤 특성을 가진 것의 비율을 모비율이라고 함. 기호로 P로 나타낸다.
- 표본 비율 : 모집단에서 임의 추출한 표본에서 어떤 특성을 가진 것의 비율을 표본 비율이라고 함. p ̂(피햇)으로 표현
- 표본 비율 p ̂에 대한 신뢰구간을 의미
: 표본을 추출했을 때, 표본의 개수 n 중에서 특정 사건 t가 발생하는 빈도를 비율로 나타낸 것
= X / n = 특정 사건 / 표본 개수

- 예시 문제,
n = 77 , 특정사건 = 5 , 신뢰구간 = 95% ,
주유해야 할 용량과 실제 주유된 용량에 차이가 있을 비율에 대한 신뢰구간 은?
: p ̂ = 5 /77 = 0.0649 , n = 77 , z_(α/2) =1.96
0.064 - 1.96 * √(0.064 *(1-0.064 )/77) ≤ p ≤ 0.064 + 1.96 * √(0.064 *(1-0.064 )/77)
0.009896 ≤ p ≤ 0.1199742 => 0.98% ≤ p ≤ 11.99%
002. 표본의 크기 결정
- 모집단의 비율을 추정하는 경우에도 표본의 크기를 어느 정도로 해야 할지 가늠해야 하는데, 신뢰구간의 오차한계를 어느 정도로 할 것인지를 먼저 정하면 적절한 표본의 개수를 결정할 수 있다.

003. 모집단 분산의 구간
- 분산( 혹은 표준편차 ) 은 평균과 비율로는 알 수 없는 분포의 특성을 설명해주기에, 의사결정을 하는데 중요한 기준이 될 수 있다.
- 분산을 분포로 나타낸 것이 x^2
-> 정규분포를 이루는 모집단이라도 분산의 분포는 x^2 분포 ( 카이제곱 분포 )로 나타남
- 분산은 제곱 값이기 때문에, 음수가 나타날 수 없음. 따라서 아래의 그래프처럼 양수 값만 나타나는 형태가 됨.
- 그래프 전체가 1

- 모집단 분산 추론에 카이제곱 분포를 이용한다.

- 예시 문제,
n(표본) = 50 , 평균 = 4.3 , 표준편차 = 2.5 , 분산을 확인하기 위해 신뢰 수준 95%에서 신뢰구간을 구하기.
: n = 50 , s^2 = 2.5 , x_(1-α/2)^2 ( = x_(0.925)^2 )= 70.22 , x_(α/2)^2 ( = x_(0.025)^2 )=31.55
49 * 2.5 / 70.22 ≤ σ^2 ≤ 49 * 2.5 / 31.55 => 1.74 ≤ σ^2 ≤ 3.88
** 사회조사 분석사 교재 참고해서 추가 / 정리하기
공부 교재 : 제대로 시작하는 기초통계학
사회조사분석사
https://www.youtube.com/watch?v=jGOqkljySu8&list=PLsri7w6p16vuDN55ZGHVYnitXs2R1Wz6q



