
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- t분포
- Statistics
- NLP
- Window Function
- update
- sql
- 자연어 논문 리뷰
- 그룹바이
- nlp논문
- 짝수
- SQL 날짜 데이터
- airflow
- 자연어 논문
- SQL코테
- sigmoid
- 설명의무
- inner join
- leetcode
- 서브쿼리
- torch
- MySQL
- 카이제곱분포
- 표준편차
- HackerRank
- LSTM
- CASE
- 코딩테스트
- 자연어처리
- 논문리뷰
- GRU
- Today
- Total
HAZEL
[ NLP : CH3. 파이토치 ] 파이토치 기초 ,텐서 , 자동 미분 ( Autograd ), 피드포워드, nn.Module, 역전파 수행 본문
[ NLP : CH3. 파이토치 ] 파이토치 기초 ,텐서 , 자동 미분 ( Autograd ), 피드포워드, nn.Module, 역전파 수행
Rmsid01 2020. 12. 18. 19:153장. 파이토치
3-1. 딥러닝 시작하기 전에
|
부품 |
요약 |
최소 |
권장 |
|
CPU |
코어 개수보다 단일 클럭이 높아야 한다. |
i5 |
i7 |
|
RAM |
메모리는 많을 수록 좋다 |
16GB |
64GB |
|
GPU |
메모리가 클수록 좋다. 하지만 메로리가 크면 비싸다. |
GTX 1060Ti |
RTX 2080Ti |
|
파워서플라이 |
비싸고 검증된 브랜드를 선택하기 |
GPU개당 500W |
- |
|
쿨링 |
중요하다. |
- |
- |
3-2. 파이토치 설치하기
0 ] 아나콘다를 설치한 후, 파이썬 버전을 확인하기

1 ] 파이토치 홈페이지에 들어가기 -> 설치 버튼(install)을 누르기.
PyTorch
An open source deep learning platform that provides a seamless path from research prototyping to production deployment.
pytorch.org

2 ] 자신의 컴퓨터 환경에 맞게 설정을 한다. 그 후, 'RUN this Command' 의 명령어를 복사해준다.

- Conda / PIP 둘다 선택해도 된다.
- pip install torch===1.7.1 torchvision===0.8.2 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
3 ] Prompt에 위의 내용을 붙인 후, 실행합니다.

4] import pytorch 해보기
import torch3-3. 왜 파이토치일까?
: 파이토치는 페이스북의 주도 아래 개발이 진행되고 있다.
: 구글이 개발한 텐서플로보다 늦게 개발된 탓에, 상대적으로 적은 유저풀을 가지고 있다.
: 그러나, 파이토치는 텐서플로에 비해 훨씬 뛰어난 생산성을 가짐.
- 장점
1) 깔끔한 코드
2) 넘파이와 뛰어난 호환성
3) Autograd : 호출 한번에 역전파 알고리즘을 수행할 수 있습니다.
4) 동적 그래프 : 연산과 동시에 동적 그래프가 생성되기 떄문에, 매우 자유롭다.
3-4. basic
3.4.1. 텐서
- 텐서는 넘파이의 배열이 ndarray와 같은 개념
- 추가로 텐서간 연산에 따른 그래프와 경사도(gradient)를 저장할 수 있다.
- 파이토치연산을 수행하기 위한 가장 기본적인 객체이다.
import torch
x = torch.Tensor ([[1,2],[ 3,4]]) # torch.Tensor를 선언하면, 실수형이 반환됨
# tensor([[1., 2.],
# [3., 4.]])
y = torch.from_numpy(np.array([[1,2],[3,4]]))
# tensor([[1, 2],
# [3, 4]], dtype=torch.int32)
import numpy as np
z = np.array([[1,2],[3,4]])
# [[1 2]
# [3 4]]
3.4.2. 자동 미분 ( Autograd )
- 파이토치는 자동으로 미분 및 역전파를 수행하는 autograd 기능을 가짐
- 대부분의 텐서 간 연산들을 크게 신경 쓸필요 없이 역전파 알고리즘을 수행하는 명령어를 호출하면 됨.
- 파이토치는 텐서들간에 연산을 수행할 때마다 동적으로 연산 그래프를 생성하여 연산의 결과물이 어떤 텐서로부터 어떤 연산을 통해서 왔는지 추정함.
- 따라서 우리가 최종적으로 나온 스칼라에 역전파 알고리즘을 통해 미분을 수행하도록 했을 때, 각 텐서는 자기 자신의 자식 노드에 해당하는 텐서와 연산을 자동으로 찾아 계속해서 역전파 알고리즘을 수행할 수 있도록 함.
import torch
x = torch.FloatTensor(2,2) # 2 x 2 의 랜덤값이 나옴
y = torch.FloatTensor(2,2)
y.requires_grad_(True)
z = ( x+ y) + torch.FloatTensor(2,2)- y.requires_grad_(True) : 텐서의 기울기를 저장한다는 의미
- y.grad 에 y에 대한 미분값이 저장됨을 의미함.
- requires_grad속성을 True로 설정하면, 그 tensor에서 이뤄진 모든 연산들을 추적(track)하기 시작한다.
- with 문법을 사용하여 연산 수행
import torch
x = torch.FloatTensor(2,2)
y = torch.FloatTensor(2,2)
y.requires_grad_(True)
with torch.no_grad():
z = (x + y) + torch.FloatTensor(2,2 )
■ 다른 예시 - 자동 미분 실습
: 값이 2인 임의의 스칼라 텐서 w를 선언하고, requires_grad를 True로 설정함. 즉, 기울기를 저장한다는 것.
import torch
w = torch.tensor(2.0, requires_grad=True)
y = w**2
z = 5*y + 3
z.backward()
# tensor(23., grad_fn=<AddBackward0>)
z = 23 이 나오는데, 이는 5 x ( 2 x 2 ) + 3 을 의미한다.
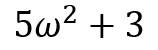
을 미분을 하면
print('수식을 w로 미분한 값 : {}'.format(w.grad))[out ] : 수식을 w로 미분한 값 : 20.0
즉, { 2 x 5 ) x 2 = 20 이 나온다는 것을 의미한다.
3.4.3. 피드포워드 ( feed forward)
: 입력층으로 데이터가 입력되고, 1개 이상으로 구성되는 은닉층을 거쳐서 마지막에는 출력층으로 출력값을 내보내는 과정
: 이전층에서 나온 출력값이 층과 층 사이에 적용되는 가중치 영향을 받은 다음 다음층의 입력값으로 들어가는 것을 의미함.
■ 선형계층 ( linear layer , 완전 연결계층 : fully- connected layer ) 구현

- R은 실수를 의미한다. 쓸때, lR < 이런식으로 표현하는 것 같다.
- 이 수식에서는 X는 벡터이지만 보통 딥러닝을 수행할 때는 미니배치를 기준으로 수행하므로, X가 2차원 행렬이라고 가정함.
- 수식은 너무 어려워보이는 것 같으나,, X는 M x N 차원이라는 것을 말한다. 아래 코드와 본다면, 16 x 10의 행렬 이라는 것이다.
- x 와 w 는 행렬곱을 해야하기 때문에, X의 N와 W의 N은 같은 길이 이어야 한다.
import torch
def linear(x, W, b) :
y = torch.mm(x, W) + b # torch.mm 행렬곱
return y
x = torch.FloatTensor(16,10)
W = torch.FloatTensor(10,5)
b = torch.FloatTensor(5)
y = linear(x, W, b)
3.4.4. nn.Module
: nn.Module이라는 클래스는 사용자가 그 위에서 필요한 모델 구조를 구현할 수 있게 함.
- nn.Module을 상속한 사용자 정의 클래스는 다시 내부에 nn.Module을 상속한 클래스 객체를 선언하여 소유할 수 있다.
- 즉, nn.Module 상속 객체 안에 nn.Module 상속 객체를 선언하여 변수로 사용할 수 있다.
- nn.Module 의 forward() 함수를 오버라이드(override/덮어쓰기)하여 피드포워드를 구현 할 수 있다.
** 오버라이드 : 상속관계에서 부모 클래스의 리소스를 자식클래스가 재정의하여 사용함.
- nn.Module의 특징을 이용하여 한번에 신경망 가중치 파라미터들을 저장 및 불러오기를 수행 할 수있다.
import torch
import torch.nn as nn
class MyLinear(nn.Module): # nn.Module 안에 nn,Nodule을 상속
def __init__(self, input_size , output_size):
super().__init__() # 상속받은 부모 클래스를 의미
self.W = torch.FloatTensor(input_size, output_size)
self.b = torch.FloatTensor(output_size)
def forward(self , x):
y = torch.mm(x, self.W) + self.b
return y
x = torch.FloatTensor(16,10)
linear = MyLinear(10, 5)
y = linear(x)
- 10개의 원소를 가진 벡터를 16개 가진 행렬x를 생성하고, 이를 위의 클래스에 통과하여, 10개의 원소를 가진 벡터는 5개의 원소를 가진 벡터로 변환됨.


- forward()에서 정의한 대로 잘 동작하는 것을 볼 수 있다. 하지만, 이처럼 W와 b를 선언하면 문제가 있다. parameters()함수는 모듈 내에 선언된 학습이 필요한 파라미터들을 반환하는 이터레이터 이다.
** 이터레이터(iterator) : 파이썬에서 반복자는 여러개의 요소를 가지는 컨테이너(리스트, 튜플)에서 각 요소를 하나씩 꺼내 어떤 처리를 수행하는 간편한 방법을 제공하는 객체
- linear 모듈 내의 학습이 필요한 파라미터들의 크기를 size()함수를 통해 확인할 수 있다.

- linear 모듈 내에는 학습 가능한 파라미터가 없다는 뜻이다.
- 신경망 학습 파라미터는 단순한 텐서가 아니기 때문에 파라미터로 등록되어야 한다.
=> 따라서, Parameter라는 클래스를 사용하여 텐서를 감싸야 한다.
import torch
import torch.nn as nn
class MyLinear(nn.Module): # nn.Module 안에 nn,Nodule을 상속
def __init__(self, input_size , output_size):
super(MyLinear, self).__init__() # 상속받은 부모 클래스를 의미
self.W = nn.Parameter(torch.FloatTensor(input_size, output_size), requires_grad= True)
self.b = nn.Parameter(torch.FloatTensor(output_size),requires_grad = True )
def forward(self , x):
y = torch.mm(x, self.W) + self.b
return y
x = torch.FloatTensor(16,10)
linear = MyLinear(10, 5)
y = linear(x)
■ 더 깔끔하게 코드 구현!
class MyLinear(nn.Module):
def __init__(self, input_size , output_size):
super(MyLinear, self).__init__()
self.linear = nn.Linear(input_size, output_size)
def forward(self, x):
y = self.linear(x)
return y
x = torch.FloatTensor(16,10)
linear = MyLinear(10,5)
3.4.5. 역전파 수행
: 피드포워드를 통해 얻은 값에서 실제 정답값과의 차이를 계산하여 오류(손실)을 뒤로 전달 (back - propagation)하는 역전파 알고리즘
- 원하는 값이 100이라고 했을때, linear의 결과값 텐서의 합과 목푯값과의 거리(error 혹은 loss)을 구하고, 그 값에 대해 bakward() 함수를 사용하여 기울기를 구함.
- 이때, 에러값은 스칼라로 표현되어야 함. 벡터나 행렬의 형태는 안됨
objective = 100
x = torch.FloatTensor(16,10)
linear = MyLinear(10, 5)
y = linear(x)
loss = (objective - y.sum())
loss.backward()- 각 파라미터의 기울기에 대해서 반복적으로 경사하강법을 사용하여 에러를 줄여나갈 수 있다.

3.4.6. Train()과 eval()
: train()과 eval() 함수를 활용하면, 사용자는 필요에 따라 모델에 대해 훈련 시와 추론 시의 모드를 쉽게 전환할 수 있다.
- nn.Module 을 상속받아 구현하고 생성한 객체는 기본적으로 훈련 모드다.
- eval()을 사용하여 추론 모드로 바꾸어주면, 드롭아웃 또는 배치 정규화와 같은 학습과 추론시 서로 다른 forward() 동작을 하는 모듈들에 대해서도 각 상황에 따라 올바르게 동장한다.
- 추론이 끝나면 다시 train을 선언하여 원래의 훈련모드로 돌아가게 해주어야한다.
** 본 게시글은 자연어 책을 공부하면서 정리한 것
출처 : 김기현의 자연어 처리 딥러닝 캠프 _ 파이토치 편



