
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- MySQL
- 코딩테스트
- CASE
- 자연어 논문 리뷰
- 그룹바이
- 표준편차
- Window Function
- SQL코테
- sql
- LSTM
- nlp논문
- sigmoid
- 자연어 논문
- 서브쿼리
- airflow
- Statistics
- inner join
- 논문리뷰
- t분포
- 자연어처리
- update
- leetcode
- 짝수
- NLP
- 설명의무
- SQL 날짜 데이터
- torch
- GRU
- 카이제곱분포
- HackerRank
- Today
- Total
HAZEL
[ Torch : 09 ] 활성화함수 : Sigmoid/ ReLU , Optimizer 본문
boostcourse 의 파이토치로 시작하는 딥러닝 기초 강의를 듣고 정리한 내용입니다.
1. 활성화 함수란?
: 입력된 데이터의 가중 합을 출력 신호로 변환하는 함수이다. Linear 한 layer를 쌓으면, linear한 연산만 가능한데, 활성화 함수를 통해 비선형 특성을 가할 수 있게 된다.
1. Sigmoid
1 ) Sigmoid 란?
시그모이드 함수의 반환값(y축)은 흔히 0에서 1까지의 범위를 가진다. 또는 -1부터 1까지의 범위를 가지기도 한다.
sigmoid가 이진 분류에서 사용될 경우, 0 ~ 1 사이의 실수 값을 출력값으로 가진다. 따라서, 0.5를 기준으로 첫 번째 class와 두 번째 class를 나눈다.

2 ) Sigmoid 함수 특성 :
1. 값이 작아질 수록 0, 커질수록 1에 수렴하며, 출력이 0~1사이로 '확률'로 나타낼 수 있다.
그로인해, 이진분류에 적합한 함수가 된다.
2. 입력값이 0이 될 수록 출력이 빠르게 변하고, 무한대가 될수록 느리가 변한다.
3. 모든점에서 미분이 가능하며, 모든 실수 입력값에 대해 출력이 정의된다.
4. 0.5로 넘나 안넘나로 범주가 구분 됨.
3 ) Sigmoid 의 문제점 ' Vanishing Gradient : 기울기 소실'
: Sigmoid의 문제점은 기울기 소실 문제이다.
: Sigmoid를 activation function으로 사용하는 모델이 있을때, 정답데이터와 예측데이터의 loss를 계산하고 미분을 통해서 gradient를 구하고, backpropagation알고리즘을 통해 뒤단으로 전파하면서 weight를 업데이트하는 식으로 학습을 한다. 여기서, 초록색 부근은 gradient값이 잘 계산되지만, 양끝에는 gradient를 구하게되면 0혹은 0에 가까운 아주 작은 값이 나오게 된다. gradient가 앞단으로 전파될때, activation funtion에서 gradient을 곱하게 되는데, 이때 아주 작은 값이 곱해지면서 뒤단에서 loss로 부터 전파되는 gradient가 소멸되는 문제가 발생할 수 있기 때문이다.

1개의 layer의 경우는 상관 없지만, 이 sigmoid function을 사용하는 layer가 많을 경우, 0에 가까운 gradient가 계속 곱해지면서 앞단에서는 거의 gradient를 전파받을 수 없게 된다.

sigmoid = torch.nn.Sigmoid(x)
2. ReLU
1 ) ReLU 란?
: activation function의 입력으로 어떤 x가 들어왔을 때, 만약에 x가 0보다 크면 x 자기 자신을 그대로 출력하고, 0보다 작은 음수의 경우에는 0으로 출력하는 함수이다.
: 수식 = f(x) = max(0,x)
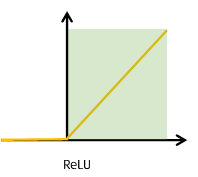
: 초록색 영역인 경우, gradient를 계산하면 1이기 때문에 Sigmoid에서 발생하는 Gradient Vanishing문제가 사라지게 된다. 그이유는 0이 곱해지지 않기 때문이다. 하지만, 음수 영역에서는 gradient가 0이기 때문에 음수로 activation되는 경우, gradient가 사라지게 되는 문제점이 있다.
sigmoid = torch.nn.relu(x)
3. 기타 활성화 함수
torch.nn.sigmoid(x)
torch.nn.tanh(x)
torch.nn.relu(x)
torch.nn.leaky_relu(x, 0.01)
4. Optimizer (최적화)
: 손실 함수(Loss Function)의 결과값을 최소화하는 모델의 파라미터(가중치)를 찾는 것을 의미한다.
: 학습속도를 빠르고 안정적이게 하는 것이다.
torch.optim 이라는 패키지에 들어가면 다양한 optimization 알고리즘이 구현되어 있다.
예전에 정리해둔 Optimizer 에 대한 내용이다.
https://hazel01.tistory.com/36
[ Deep Learning 02 ] 경사하강 학습법 ( Gradient Descent ) , 옵티 마이저 ( Optimizer )
Deep Learning 02. 경사하강 학습법 1. 모델을 학습하기 위한 기본적인 용어 1.1. 학습 매개변수 ( Trainable Parameters ) : 학습 과정에서 값이 변화하는 매개변수 : 매개변수가 변화하면서, 알고리즘 출력이
hazel01.tistory.com
※ 옵티마이저의 발전 과정

출처 : https://www.slideshare.net/yongho/ss-79607172

- 옵티마이저의 발전과정은 gradient 와 learning rate 를 어떻게 수정했냐에 따라서 달라진다.
- Gradient 수정 : Momentum , Nag
- Learning Rate 수정 : Adagrad, RMSProp, AdaDelta
- 두가지를 합한 것 : Adam , Nadam
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)


