
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- NLP
- SQL코테
- 자연어 논문
- 코딩테스트
- CASE
- nlp논문
- update
- 카이제곱분포
- 자연어 논문 리뷰
- MySQL
- GRU
- Window Function
- sql
- 그룹바이
- SQL 날짜 데이터
- LSTM
- 논문리뷰
- 자연어처리
- 짝수
- airflow
- leetcode
- HackerRank
- inner join
- torch
- t분포
- sigmoid
- 설명의무
- 서브쿼리
- Statistics
- 표준편차
Archives
- Today
- Total
HAZEL
Pandas - 데이터 분석할 때 유용한 Groupby 본문
데이터를 다루기 위해, 여러 변수를 만지다 보면, groupby가 굉장히 유용하다는 것을 느낀다.
그래서, 기초부터 응용 버전까지 한 번에 정리하려고 한다.
0. Groupby 란,
SQL groupby 명령어와 같은 느낌인데, 데이터를 split -> apply -> combine 하는 과정을 거쳐서 연산한다.
아래에서 다양한, 그룹바이 예시를 하기 위해서 데이터 프레임을 만들어 준다.
1. groupby를 하는 방법 : 기본적인 groupby
01. 한개 열을 기준으로 groupby : 집계
그룹바이는, 그룹 바이만 하면 안 되고, 집계 함수를 같이 써주어야 내가 원하는 데이터 프레임 형태가 된다.
묶어 주고 싶은 컬럼을 by = [' col ' ] 넣어주면 된다. by는 생략해도 된다.
아래 코드는 최소 수량을 알기 위해, min을 사용하였지만, 다른 집계 함수들도 사용할 수 있다.
[ count, min, mean, sum, max, cumsum ]
# min: 상품번호별 판매된 최소 수량
df.groupby(by=['product_id']).min()
그룹바이를 통해, P1을 가지고 있는 ROW중에서 가장 최소인 것들만 뽑아진 것을 확인할 수 있다.
02. 두개 이상의 열을 기준으로 groupby 하기
두 개 이상의 열을 기준으로도, 그룹바이를 할 수 있다.
그러면, index 가 multi index 가 된다.
df_grouped = df.groupby(['product_id','user_id']).sum()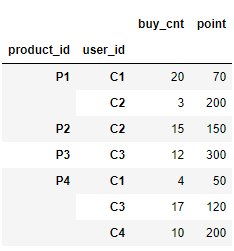
** 이렇게 인덱스 형태가 되면, 데이터를 다룰 때 귀찮아질 때가 있다. 그럴 때, groupby안에서 as_index를 False로 넣어주면, 기준 칼럼이 인덱스로 가지 않는다.
df_grouped = df.groupby(['product_id','user_id'], as_index = False).sum()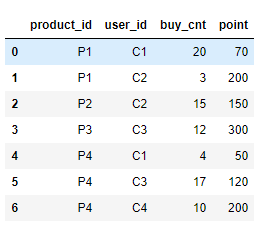
** 아래의 코드처럼 특정 컬럼 이름을 명시해주면, 그 컬럼만 적용받을 수 있다.
df.groupby(['product_id','user_id'])['point'].sum()
2. grouby를 한 후, index 를 다루기
3. groupby된 데이터를 가지고 원하는 정보 추출
'DATA ANALYSIS > Python with Data' 카테고리의 다른 글
| [ Pandas ] 데이터프레임 데이터의 '{}' 안에 있는 값 추출하기 (0) | 2022.05.09 |
|---|---|
| 1. Pandas - Datetime() 한번에 정리하기 (0) | 2021.01.20 |
'DATA ANALYSIS/Python with Data' Related Articles
more

